Darwinian data structure selection Basios et al., FSE’18
GraphIt may have caught your attention for the success of its approach, but I suspect for many readers it’s not something you’ll be immediately applying. Darwinian Data Structures (DDSs) on the other hand looks to be of immediate interest to many Java and C++ projects (and generalises beyond those languages).
What I would have called an ADT (e.g., a List), the authors call Darwinian Data Structures. The ‘Darwinian’ part comes from the fact that ADTs have multiple concrete implementations, and Artemis, “a multi-objective, cloud-based search-based optimisation framework” finds the best implementation class (e.g. ArrayList, LinkedList) for your specific use case. It does this using the NSGA-II genetic algorithm-based optimiser in the current implementation.
In brief, Artemis finds the places in your code where you are using an ADT, and explores the possible concrete instantiation space for those ADTs using your test suite as a guide to performance. Then it outputs the transformed source. You might be wondering whether e.g. LinkedList vs ArrayList makes that big a difference in most real world projects:
Artemis achieves substantial performance improvements for every project in 5 Java projects from DaCapo benchmark, 8 popular projects, and 30 uniformly sampled projects from GitHub. For execution time, CPU usage, and memory consumption, Artemis finds at least one solution that improves all measures for 86% (37/43) of the projects. The median improvement across the best solutions is 4.8%, 10.1%, and 5.1% for runtime, memory, and CPU usage.
For example, consider this code from google-http-java-client, which currently uses ArrayList :

Switching to LinkedList and comparing performance over the same test set for 30 runs, we get a median 46% reduction in execution time.
We are interested not just in searching the space of Darwinian data structures, but also tuning them via their constructor parameters.
For example, choosing an appropriate initial capacity size for an ArrayList.
End-to-end Artemis works like this:
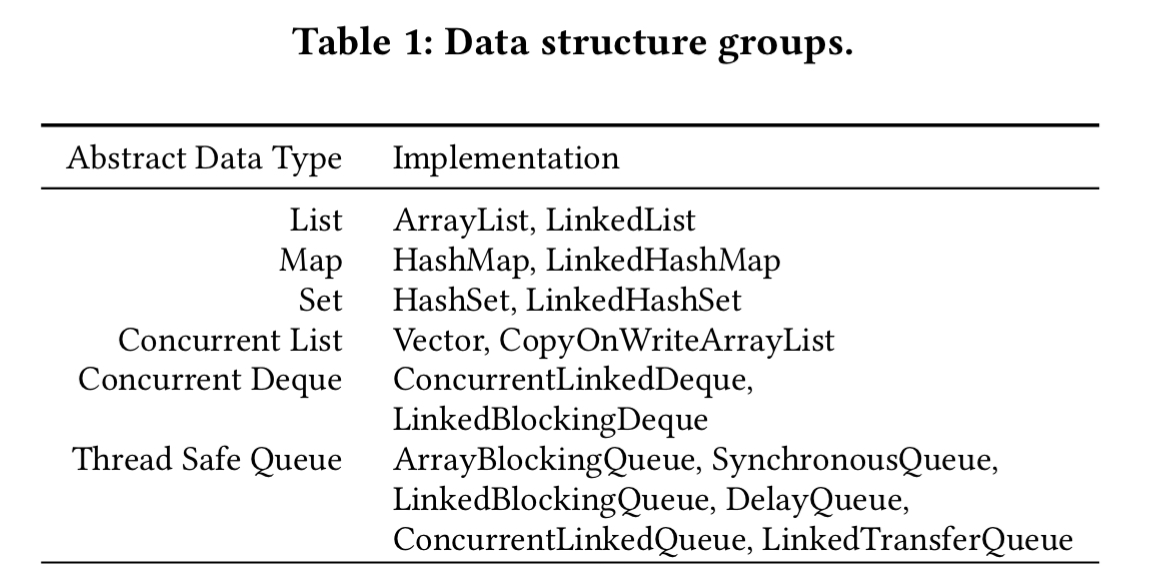
There’s a one-off up-front exercise to analyse the collections library / libraries of interest and build a dictionary that describes the search space. Then given the source code and test suite of a project Artemis explores the AST to find uses of DDSs, outputting a templated version of the source code with replacement points for each usage. A search algorithm is then used to find the best choice in each location, with the test suite being used to judge performance.
Finding candidate program points for DDS substitution
Given an AST, it’s easy to find declarations using the abstract data type (e.g. List), but in the code bases under study the authors also found many cases where programmers had over-specified, using a concrete type for variable and parameter type declarations, e.g.

Artemis will apply further transformations to replace these with the abstract type instead, thus permitting DDS exploration.
Many programs make extensive use of collection types, resulting in a very large overall search space. Artemis profiles the input program while running the test suite to identify the highest value points in the program to explore and thus prunes the search space. Profiling is done using the JConsole profiler.
Searching for the best parameters
The overall search space for a given DDS consists of all the possible concrete implementation types, together with the parameter spaces for their respective constructor arguments.
For each generation, NSGA-II applies tournament selection, followed by a uniform crossover and a uniform mutation operation. In our experiments, we designed fitness functions to capture execution time, memory consumption, and CPU usage. After fitness evaluation, Artemis applies standard non-dominated selection to form the next generation. Artemis repeats this process until the solutions in a generation converge. At this point, Artemis returns all non-dominated solutions in the final population.
In the evaluation, the initial population size is set to 30, with a limit of 900 function evaluations.
To assess fitness Artemis relies on running the test suite. Therefore the results will only apply to production use cases to the extent that your test suite mirrors production usage.
Even though performance test suites are a more appropriate and logical choice for evaluating the non-functional properties of the program, most real world programs in GitHub do not provide a performance suite. For this reason, we use the regression test suites to evaluate the non-functional properties of the GitHub projects of this study whenever a performance test suite is not available.
Test suite execution time is measured using the Maven Surefire plugin, with profiling done by JConsole. Each generated solution is run for at least 30 simulations, with start-up/ JVM warm-up runs not counting towards this total. (See ‘[Virtual machine warmup blows hot and cold](https://blog.acolyer.org/2017/11/07/virtual-machine-warmup-blows-hot-and-cold/’ for some of the difficulties of performance measurements on the JVM.)
Evaluation
Artemis is evaluated on three different groups of projects. The first group comprises 8 popular GitHub projects selected for their good test suites and diversity: http-java-client, jOOL, jimfs, gson, cglib, solo, GraphJet, and joda-time (see https://darwinianoptimiser.com/corpus). The second corpus is based on the DaCapo benchmarks, which were built from the ground up to be representative of usage in real world projects. DaCapo is a little dated now though (2006, and Java 1.5, but a refresh is on the way) and only 5 out of 14 benchmarks could be used in the end. For this reason, a third corpus of 30 projects uniformly sampled from GitHub such that they have a defined build system etc. was also added.
The selected projects include static analysers, testing frameworks, web clients, and graph processing applications. Their sizes vary from 576 to 94k lines of code with a median of 14,881. Their popularity varies from 0 to 5462 stars with a median of 52 stars per project. The median number of tests is 170 and median line coverage ratio is 72%.
The four key findings from the evaluation are as follows:
- Artemis finds optimised variants that outperform the original program in at least one measure for all programs in our representative corpus. For 88% of the programs the solution found by Artemis outperformed the original on all measures.
- Artemis improves the median across all programs in our corpus by 4.8% execution time, 10.2% memory consumption, and 5.1% CPU usage. For example, here are the charts for the GitHub programs:
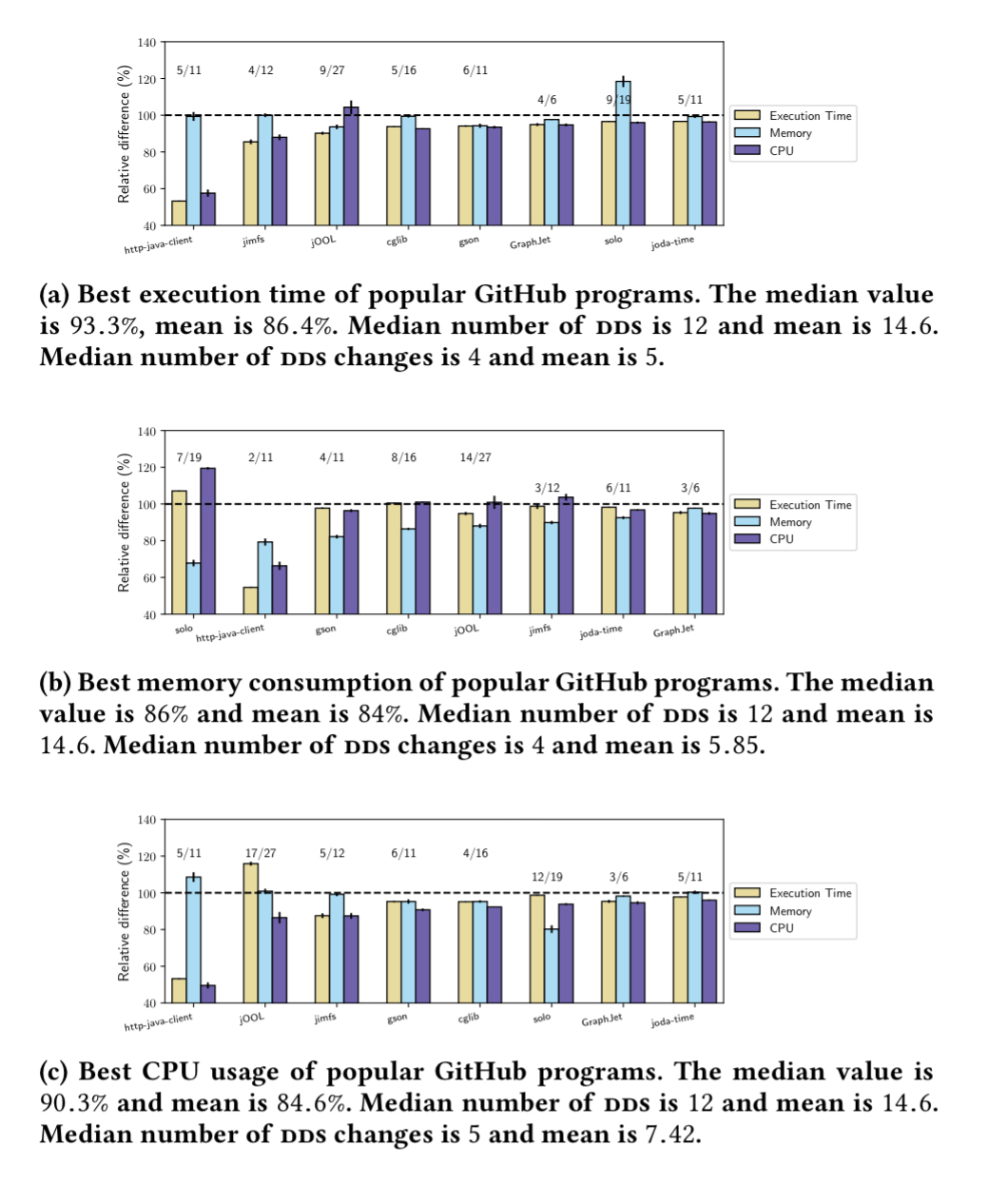
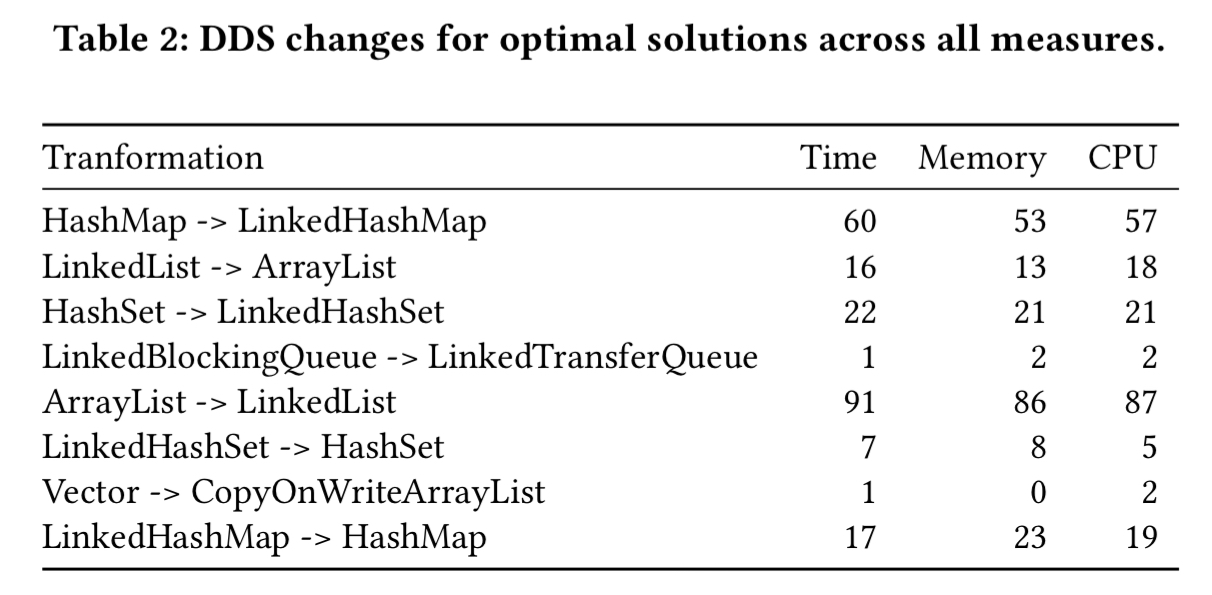
- Artemis extracted a median of 12 Darwinian data structures from each program and the optimal solutions had a median of 5 data structure changes from the original versions of the program. The most common changes made by Artemis across the corpus are shown in the table below.
- The cost of using Artemis is negligible, with an average (Azure cloud spend) of £1.25 per project, providing engineers with insights about the optimal variants of the project under optimisation. (Across the corpus, the cost of running an Artemis optimisation ranges from £0.02 to £7.86).
… we conclude that Artemis is a practical tool for optimising data structures in large real-world programs.
Appropriately packaged and with the right level of polish, Artemis could make a very nice cloud service: authorise it on your GitHub repository, and receive pull requests with source code changes and associated performance impact assessments. Alternatively, since nothing matches the performance profile of production traffic like production traffic, you could imagine an integration with an A/B testing and CD pipeline (aka ‘Continuous Experimentation).