BEAT: asynchronous BFT made practical Duan et al., CCS’18
Reaching agreement (consensus) is hard enough, doing it in the presence of active adversaries who can tamper with or destroy your communications is much harder still. That’s the world of Byzantine fault tolerance (BFT). We’ve looked at Practical BFT (PBFT) and HoneyBadger on previous editions of The Morning Paper. Today’s paper, BEAT, builds on top of HoneyBadger to offer BFT with even better latency and throughput.
Asynchronous BFT protocols are arguably the most appropriate solutions for building high-assurance and intrusion-tolerant permissioned blockchains in wide-are (WAN) environments, as these asynchronous protocols are inherently more robust against timing and denial-of-service (DoS) attacks that can be mounted over an unprotected network such as the Internet.
The best performing asynchronous BFT protocol, HoneyBadger, still lags behind the partially synchronous PBFT protocol in terms of throughput and latency. BEAT is actually a family of five different asynchronous BFT protocols that start from the HoneyBadger baseline and make improvements targeted at different application scenarios.
Unlike HoneyBadgerBFT, which was designed to optimize throughput only, BEAT aims to be flexible and versatile, providing protocol instances optimized for latency, throughput, bandwidth, or scalability (in terms of the number of servers).
The BEAT protocols divide into two groups: those supporting full (general) state-machine replication (SMR), as required e.g. for smart contract use cases (BEAT0, BEAT1, BEAT2); and those that support BFT storage (append-only ledger) use cases only (BEAT3, BEAT4).
The following table summarises the BEAT family and the key distinguishing features of each member.

(Enlarge)
{kind=link}
There’s a lot of ground to cover here, but I’ll do my best to give you an overview. Alongside the BEAT protocols themselves, the paper also includes two new building blocks: the generalized fingerprinted cross-checksum and an asynchronous verifiable information dispersal (AVID) algorithm.
The HoneyBadger baseline
HoneyBadger supports ACS (the asynchronous common subset) meaning that it provides these guarantees:
- Validity: if a correct server delivers a set
, then
and
correct servers.
- Agreement: if a correct server delivers a set
- Totality: if
correct servers submit an input, then all correct servers deliver an output.
HoneyBadger uses reliable broadcast (RBC) and asynchronous Byzantine binary agreement (ABA) protocols to achieve its aims. Threshold signatures are used to provide common coins for ABA, and threshold encryption is used to avoid censorship and achieve liveness.
In a threshold scheme the partial outputs (e.g. decryption shares) of at least t participants need to be combined in order to recover (decrypt) the intended value.
BEAT0: improved security and performance
BEAT0, our baseline protocol, incorporates a more secure and efficient threshold encryption, a direct instantiation of threshold coin-flipping (instead of using threshold signatures), and more flexible and efficient erasure-coding support.
BEAT0’s threshold encryption uses the TDH2 scheme by Shoup and , providing 128-bit security under elliptic curve cryptography. This gives stronger security and better performance than the scheme used in HoneyBadger.
In place of the zfec erasure coding library used by HoneyBadger, which supports only Reed-Solomon codes and at most 128 servers, BEAT uses the Jerasure library giving access to more efficient erasure coding schemes and lifting the replica restriction.
BEAT1: lower latency
Via a careful study of latency for each HoneyBadgerBFT subprotocol, we find that (1) most of the latency comes from threshold encryption and threshold signatures, and (2) somewhat surprisingly, when the load is small and there is low contention, erasure-coded reliable broadcast (AVID broadcast) causes significant latency.
BEAT1 swaps out the AVID broadcast protocol of BEAT0 for a replication-based reliable broadcast protocol, Bracha’s broadcast. Under small loads BEAT1 has lower latency. With small batch sizes BEAT1’s throughput is higher than HoneyBadger / BEAT0, but with larger batch sizes throughput is down by 20-30%.
BEAT2: causal ordering
BEAT2 builds on BEAT1 and also opportunistically moves the use of threshold encryption to the client side.
In BEAT2, when the ciphertexts are delivered, it is too late for the adversary to censor transactions. Thus, the adversary does not know what transactions to delay, and can only delay transactions from specific clients. BEAT2 can be combined with anonymous communication networks to achieve full liveness. BEAT2 additionally achieves causal order, which prevents the adversary from inserting derived transactions before the original, causally prior transactions.
BEAT3: higher throughput for storage use cases
BEAT3 is the first member of the BEAT family targeted for BFT-storage use cases (as opposed to general SMR).
Recall that the safety and liveness properties of BFT storage remain the same as those of general SMR, with the only exception that the state may not be replicated at each server (but instead may be erasure-coded). BEAT3 can be used for blockchain applications that need append-only ledgers, and specific blockchains where the consensus protocol serves as an ordering service, such as Hyperledger Fabric.
Whereas so far we’ve been using a reliable broadcast protocol (AVID), BEAT3 replaces this with a bandwidth-efficient information dispersal scheme called AVID-FP. To disperse a block 
")
")

")
")
")
AVID-FP is a bandwidth-efficient AVID (asynchronous verifiable information dispersal) protocol using fingerprinted cross-checksum. In AVID-FP, given a block B to be dispersed, the dealer applies an (m,n) erasure coding scheme, where
and
… then it generates the corresponding fingerprinted cross-checksum for B with respect to the erasure coding scheme.
Each server verifies the correctness of its fragment with respect to the fingerprint cross-checksum, “and then, roughly speaking, leverages the (much smaller) fingerprinted cross-checksum in place of the fragment in the original AVID protocol.”
An (n,m) fingerprinted cross-checksum contains a cross-checksum array of n values, and a fingerprint array of m values. The ith entry in the checksum array contains the hash of the ith coded fragment. See section 4 in the paper for details of the fingerprint array usage.
BEAT4: partial reads
BEAT4 further reduces read bandwidth using a novel erasure-coded reliable broadcast protocol called AVID-FP-Pyramid. This supports use cases where clients only need to read a fraction of a data block. AVID-FD-Pyramid is based on pyramid codes, which trade space for access efficiency in erasure-coded storage systems (about 10% extra space requirement for a 50% drop in access overhead). Pyramid codes can be efficiently built from any (n, m) systematic and MDS (maximum distance separable) code. See section 4 in the paper for brief details, or Huang et al. for an in-depth treatment. BEAT4 uses a 2-level pyramid scheme which can tolerate one failure in each level, and is able to reduce read bandwidth by 50%. Full details are in section 9 of the paper.
Evaluation
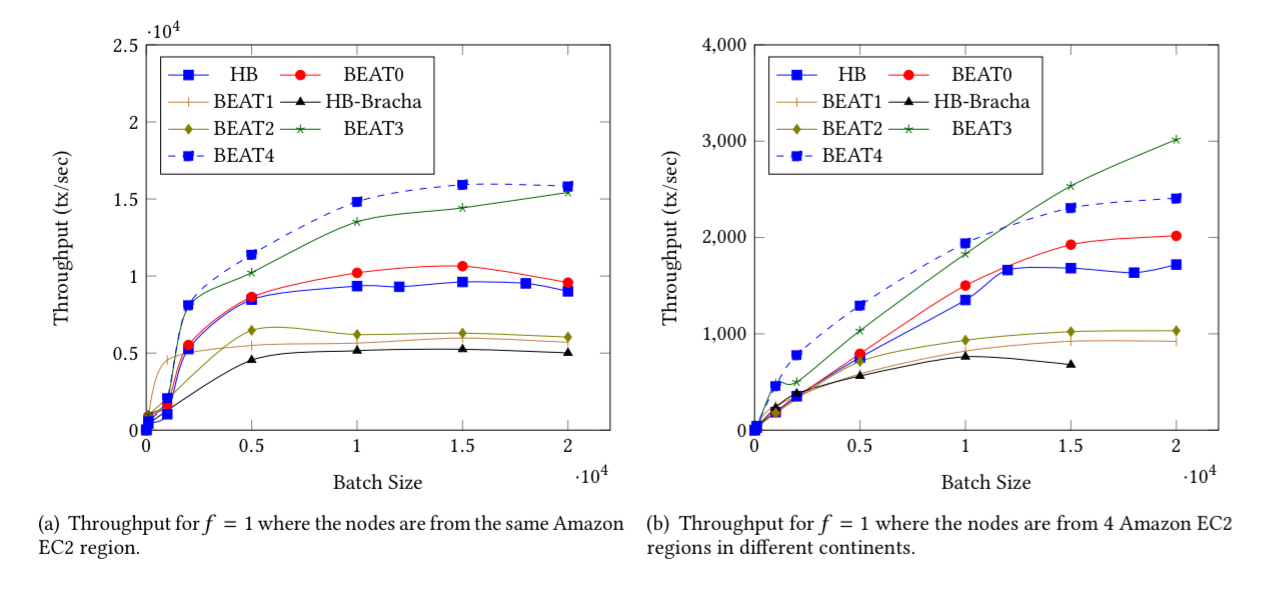
The evaluation is conducted on EC2 with up to 92 nodes from ten different regions in five different continents, using a variety of network sizes and batch sizes. In the figures that follow, 


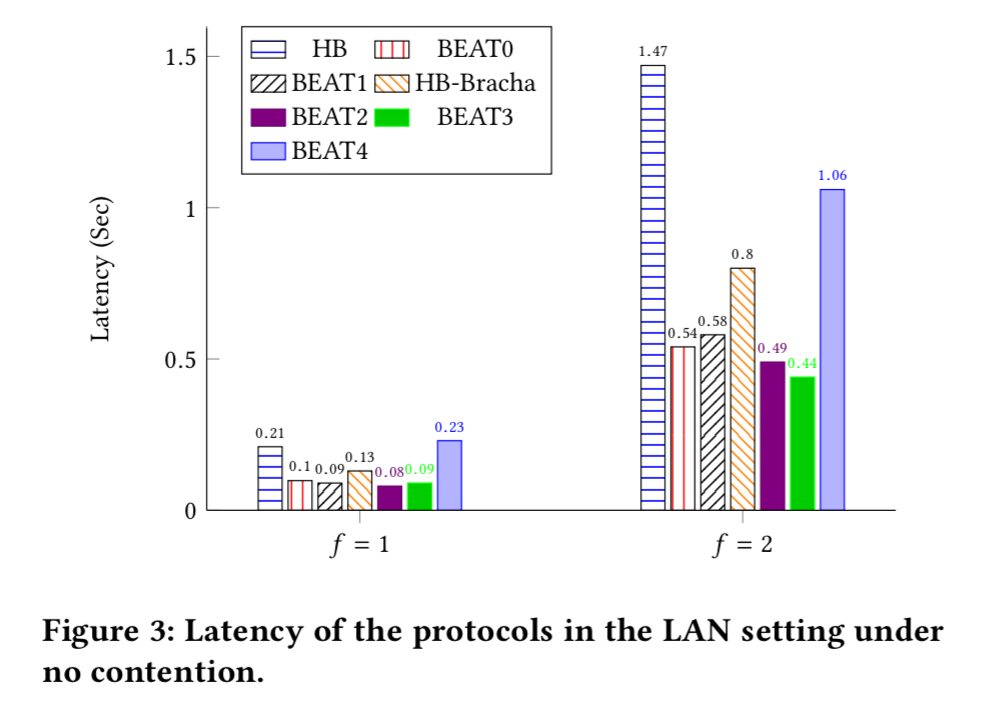
When f=1, BEAT0, BEAT1, BEAT2, and BEAT3 are around 2x faster than HoneyBadger, and when f becomes larger, they are even faster than HoneyBadger. When f = 1, BEAT4 is about as fast as HoneyBadger… As f increases, HoneyBadger is much slower than BEAT4.
For throughput, BEAT0 slightly outperforms HoneyBadger. BEAT1 and BEAT2 achieve higher throughput than HoneyBadger with small batch sizes, but have 20-30% lower throughput at larger batch sizes. BEAT3 and BEAT4 outperform all the other protocols consistently.
If this write-up has captured your interest, I highly encourage you to go an and read the full paper which contains significantly more detail than I was able to convey here.