Generalized data structure synthesis Loncaric et al., ICSE’18
Many systems have a few key data structures at their heart. Finding correct and efficient implementations for these data structures is not always easy. Today’s paper introduces Cozy (https://cozy.uwplse.org), which can handle this task for you given a high-level specification of the state, queries, and update operations that need to be supported.
Cozy has three goals: to reduce programmer effort, to produce bug-free code, and to match the performance of handwritten code. We found that using Cozy requires an order of magnitude fewer lines of code than manual implementation, makes no mistakes even when human programmers do, and often matches the performance of handwritten code.
Let’s start out by looking at four case studies from the evaluation, to get a feel for where Cozy applies.
- ZTopo is a topological map viewer implemented in C++. A core data structure is the map tile cache for map tiles that are asynchronously loaded over the network and cached on disk or in memory.
- Sat4j is a Boolean sat solver implemented in Java. A core data structure is the variable store.
- Openfire is a large scalable IRC server implemented in Java. It’s in-memory contact manager is extremely complex (and has been a frequent source of bugs).
- Lucene is a search engine back-end implemented in Java. It uses a custom data structure that consumes a stream of words and aggregates key statistics about them.
Starting from a succinct high-level specification, Cozy can generate implementations for all of these data structures, requiring far fewer lines of code for the Cozy specs than for the handwritten implementations:
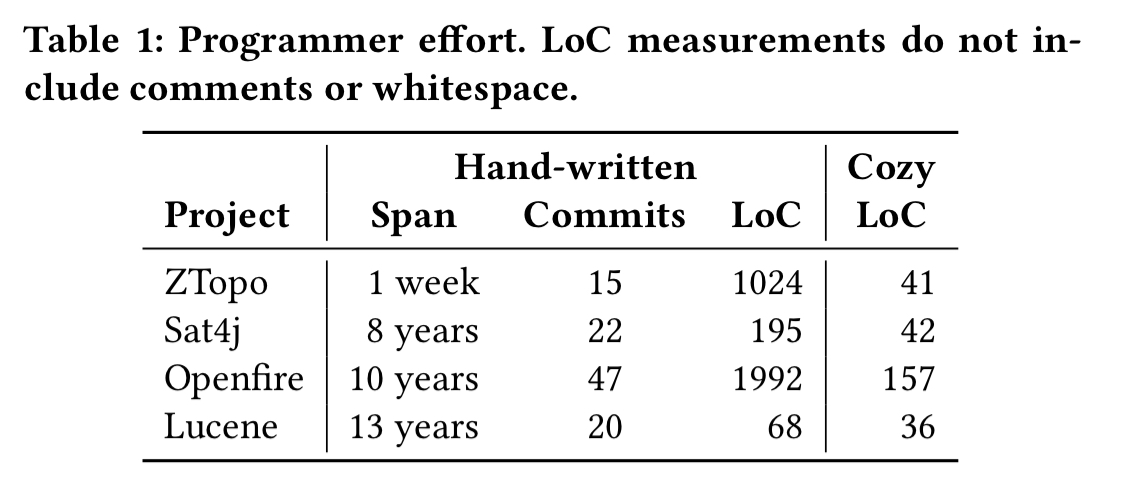
Because the specifications are shorter, simpler, and more abstract, they are much easier to understand. Programmers writing specifications are therefore less likely to make mistakes, and mistakes will be easier to discover, diagnose, and correct. The specifications also serve as concise, unambiguous documentation.
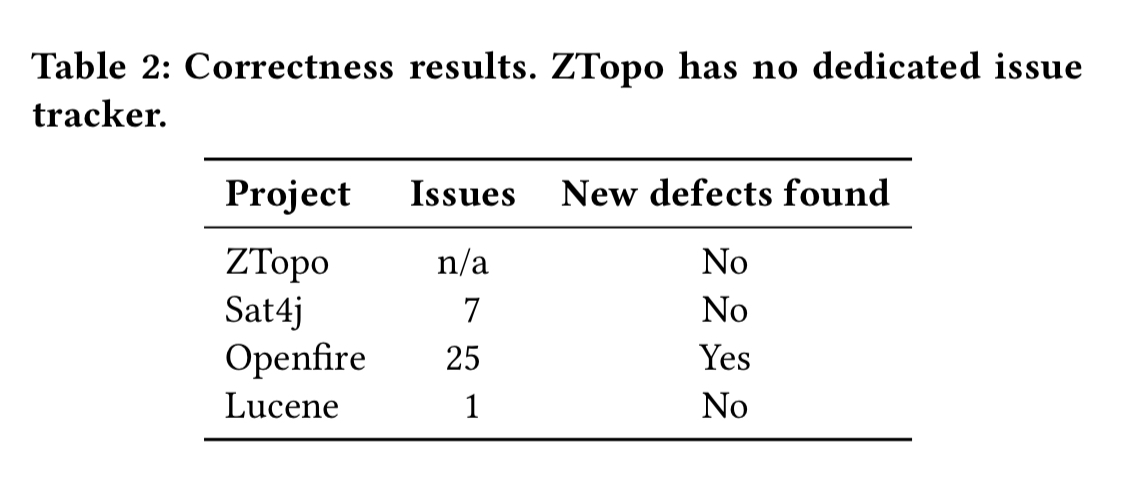
All the tests from the projects still pass with Cozy’s implementations. Looking at previous reported and fixed bugs, we can see that had Cozy been used in the first place, many bugs would have been prevented:
Cozy’s code is also competitive with handwritten code when it comes to performance:
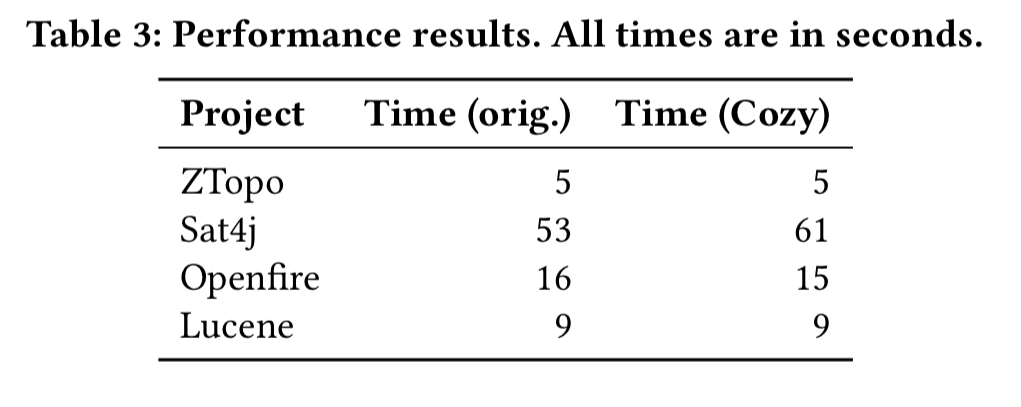
The only case where it doesn’t match or exceed the handwritten implementation is Sat4j. Here the handwritten code exploits some facts about the data that Cozy doesn’t know – variable IDs can be used as indexes into an array since they always fall between zero and a known maximum bound. Cozy must insert safety checks because it doesn’t know this.
Hopefully that has whet your appetite to learn more about how Cozy works. Let’s take a look under the hood!
Cozy’s high-level algorithm
Cozy starts with a high-level specification of the data structure, from which it constructs an initial implementation. Then it uses guided exploration to iteratively search for better implementations. Each iteration consists of two steps: query synthesis followed by “incrementalisation”. For the case studies above, Cozy was left to explore for three hours. You can stop the exploration at any point, because the implementations Cozy generates are always correct.
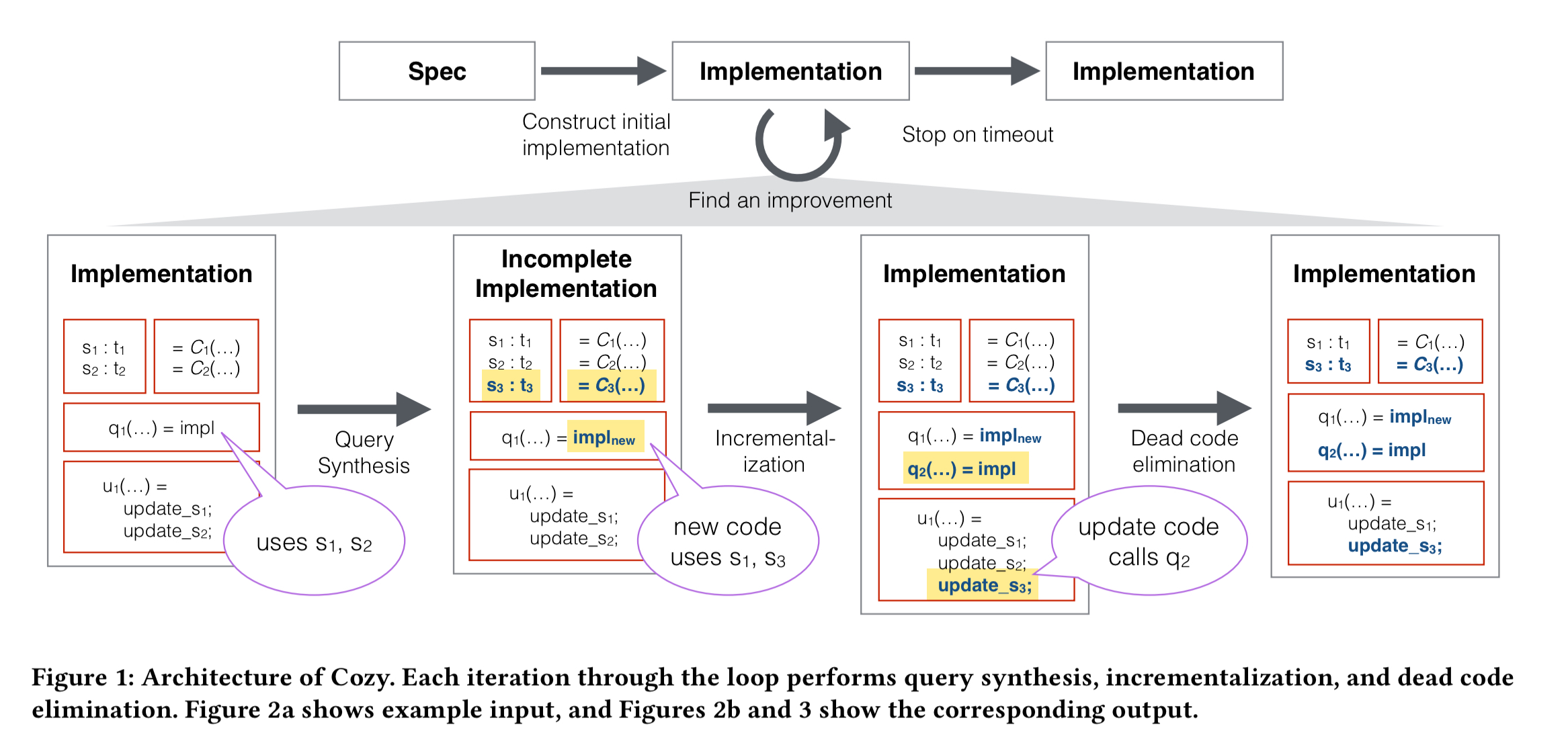
We’ll use a simplified version of the Openfire data structure as a running example. In Openfire, a user’s contact list is computed based on the groups that each user belongs to. The data structure needs to be able to efficiently answer the question “should user u1 appear in the contacts of user u2?”. The query method visible defines this relationship. A Cozy specification declares the abstract state maintained by the data structure, the queries that must be supported, and the update operations that modify data. Here’s an example for Openfire:

As specified above, visible runs in O(|groups| x |members) time. After a few rounds, Cozy will find an implementation that runs in O(g) time, where g is the maximum number of groups that any one user belongs to.
Cozy generates an initial data representation using three fields, one for each component of the abstract state. For each field in a representation, Cozy also generates a concretization function to compute the field’s representation from the abstract state. With the initial implementation, these functions are simple selectors:
v1(users, groups, members) = users
v2(users, groups, members) = groups
v3(users, groups, members) = members
Now every query and update operation can be rewritten in terms of these fields by simple substitution. So visible becomes:

This gives us a baseline implementation from which we can start to look for improvements.
In this example, after a few steps Cozy ends up with a Map-based representation that looks like this:

To go along with this new representation, Cozy also generates new concretization functions:

The new representation and implementation generated by the query synthesis step above doesn’t keep the new state variables s1, s2, and s3 up to date when join is called. The incrementalization step restores correct functioning by adding code to join to update the new state variables.
A simple but inefficient solution would be to recompute the value of each concrete state variable from scratch. Because an update usually makes a small change to the abstract state, Cozy produces an incremental update that makes small changes to the concrete state in response to a small change to the abstract state.
The update procedure is rephrased as a set of queries that compute the changes that should take place, together with a simple hardcoded snipped that applies the computed changes.
Here’s the code Cozy produces to update the concrete state when a user joins a group:
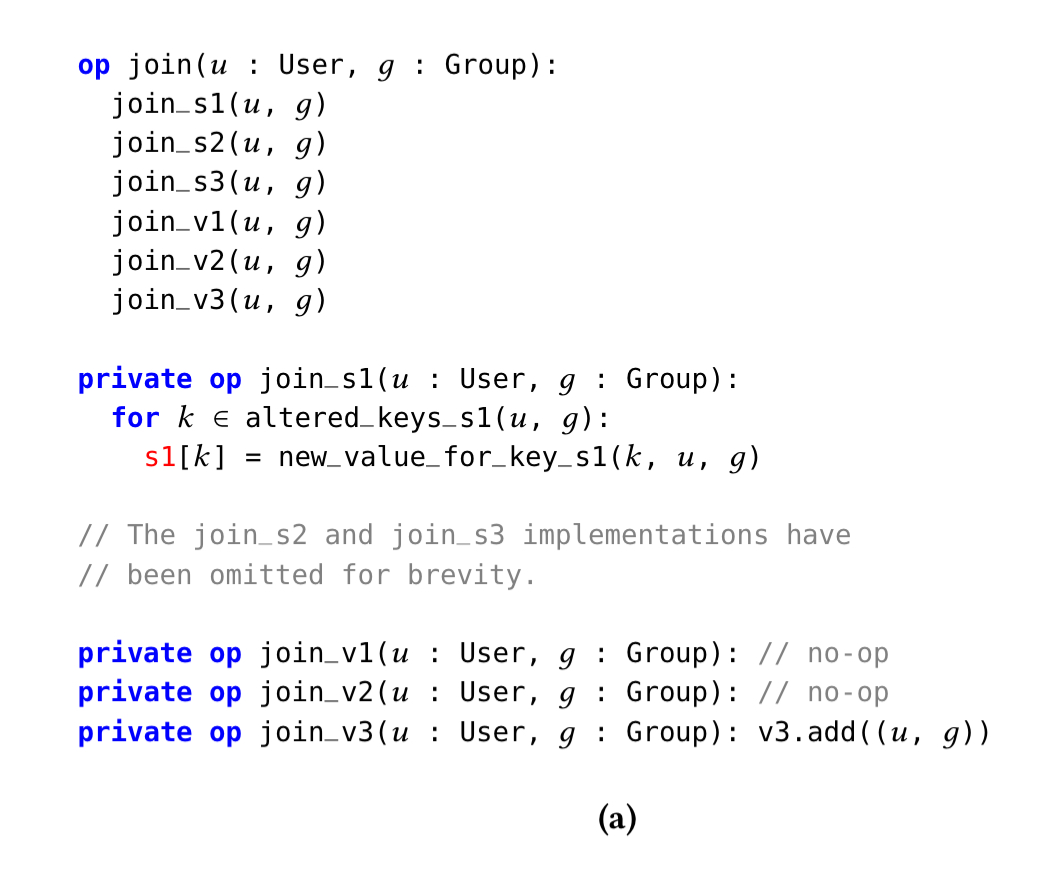
This code has introduced two new query operations: altered_keys_s1 and new_value_for_key_s1.

These new queries will be added to the query set for the data structure and optimised by the query synthesiser in future optimisation rounds.
At the end of each improvement step, a dead code elimination pass gets rid of unused variables (v1, v2, and v3 can now be eliminated in this example). All code that keeps those variables up to data can also be eliminated. Cozy uses a mark-and-sweep algorithm to do this housekeeping.
The details
Cozy’s core specification language looks like this:

The Cozy specs that users write contain sugared forms (e.g.) len(X) that are desugared into this core language. When I first started reading about Cozy, I initially expected it to have a full armoury of internal data structures at its disposal, but actually Cozy does everything today using maps!
We plan to extend Cozy with additional primitives for heaps, trees, and other efficient data structures in the future. For the case studies we examined, maps alone are sufficient to discover efficient implementations.
When searching for better query implementations, Cozy using multiple threads, each thread searching in parallel. (Which reminds me, what guarantees does Cozy give regarding concurrent access to the data structures it generates? I couldn’t see anything in the paper about this. That seems pretty important given the use cases…). There are two key parts to the search strategy: how to generate candidates, and how to evaluate candidates.
To bias the search towards useful expressions, Cozy adds a small number of handwritten diversity rules into the mix. Whenever Cozy considers a new candidate expression, it applies these rules and also considers the resulting expressions.

In practice, Cozy’s enumerative search machinery does not function well without the diversity rules, and vice-versa.
Cozy uses equivalence class deduplication to keep the search space manageable. Given a set of example inputs (produced by the verifier), if two expression produce the same output on every example, Cozy uses its cost model to decide which version to keep. The cost model looks like this:

With new queries synthesised, Cozy uses pre-defined update sketches for different types. For example, with maps the update sketch finds keys whose values have changed and updates each one in the map.

The last word
Cozy is effective because incrementalization allows it to implement both pure and imperative operations using only a query synthesizer. A high-quality cost function and diversity injection make the query synthesizer powerful and practical… Our case studies demonstrate that data structure synthesis can improve software development time, correctness, and efficiency.