Reducing DRAM footprint with NVM in Facebook Eisenman et al., EuroSys’18
(If you don’t have ACM Digital Library access, the paper can be accessed either by following the link above directly from The Morning Paper blog site).
…to the best of our knowledge, this is the first study on the usage of NVM devices in a commercial data center environment.
We’ve been watching NVM coming for some time now, so it’s exciting to see a paper describing its adoption within Facebook. MyRocks is Facebook’s primary MySQL database, and is used to store petabytes of data and to serve real-time user activities. MyRocks uses RocksDB as the storage engine, and a typical server consumes 128GB of DRAM and 3 TB of flash. It all seems to work well, so what’s the problem? Spiralling costs!
As DRAM facing major scaling challenges, its bit supply growth rate has experienced a historic low. Together with the growing demand for DRAM, these trends have led to problems in global supply, increasing total cost of ownership (TCO) for data center providers. Over the last year, for example, the average DRAM DDR4 price has increased by 2.3x.
Just using less DRAM per server isn’t a great option as performance drops accordingly. So the big idea is to introduce non-volatile memory (NVM) to pick up some of the slack. NVM is about 10x faster than flash, but still over 100x slower than DRAM. We can make up for the reduction in performance over DRAM by being able to use much more NVW due to the lower cost. So we move from a two-layer hierarchy with DRAM cache (e.g. 96GB) and flash to a three-layer hierarchy with a smaller amount of DRAM (e.g. 16GB), a larger NVM cache layer, and then flash. As of October 23rd, 2017 16GB of NVM could be picked up on Amazon for $39, whereas 16GB of DRAM cost $170.

We present MyNVM, a system built on top of MyRocks, that significantly reduces the DRAM cache using a second-layer NVM cache. Our contributions include several novel design choices that address the problems arising from adopting NVM in a data center setting…
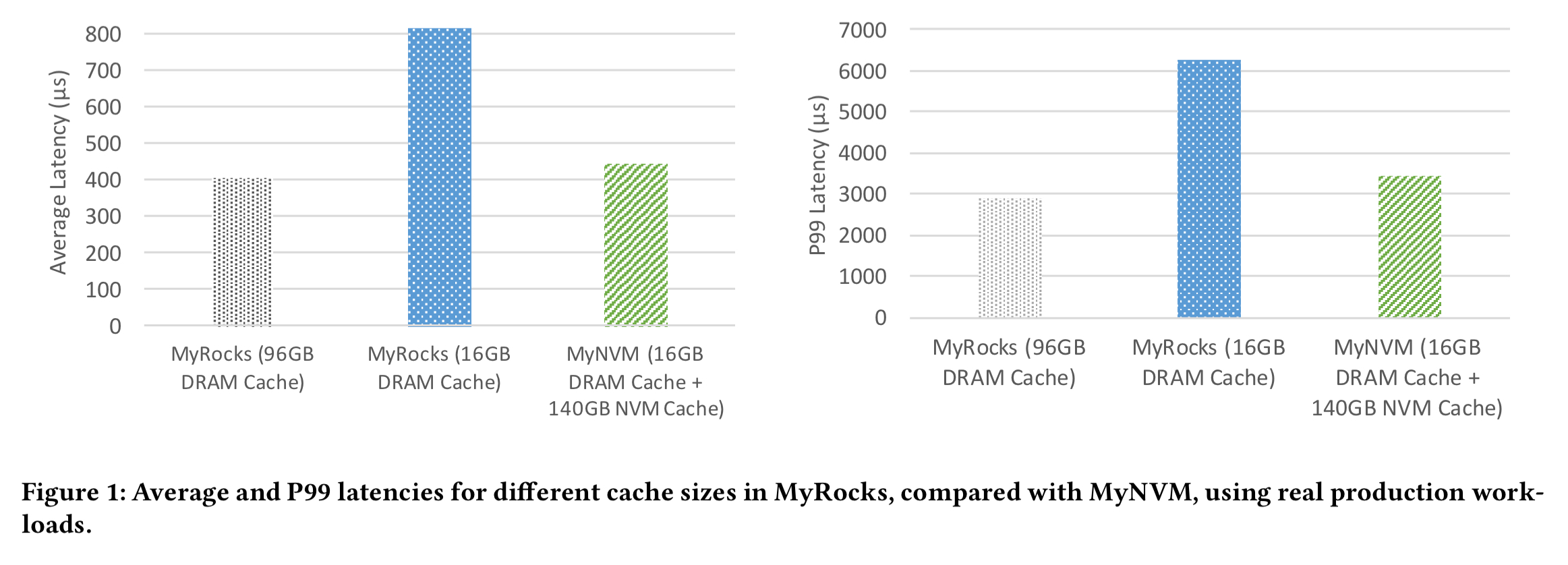
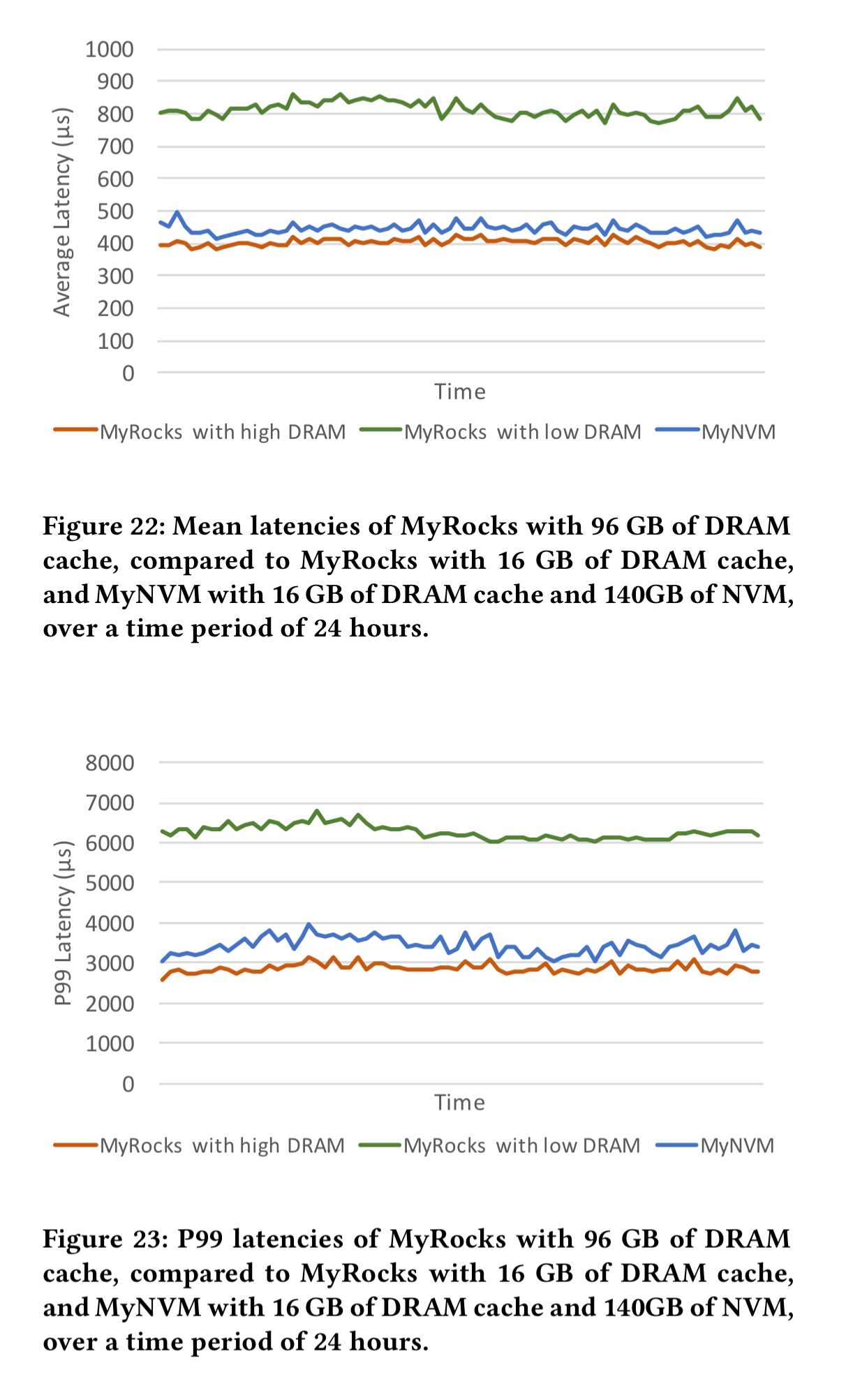
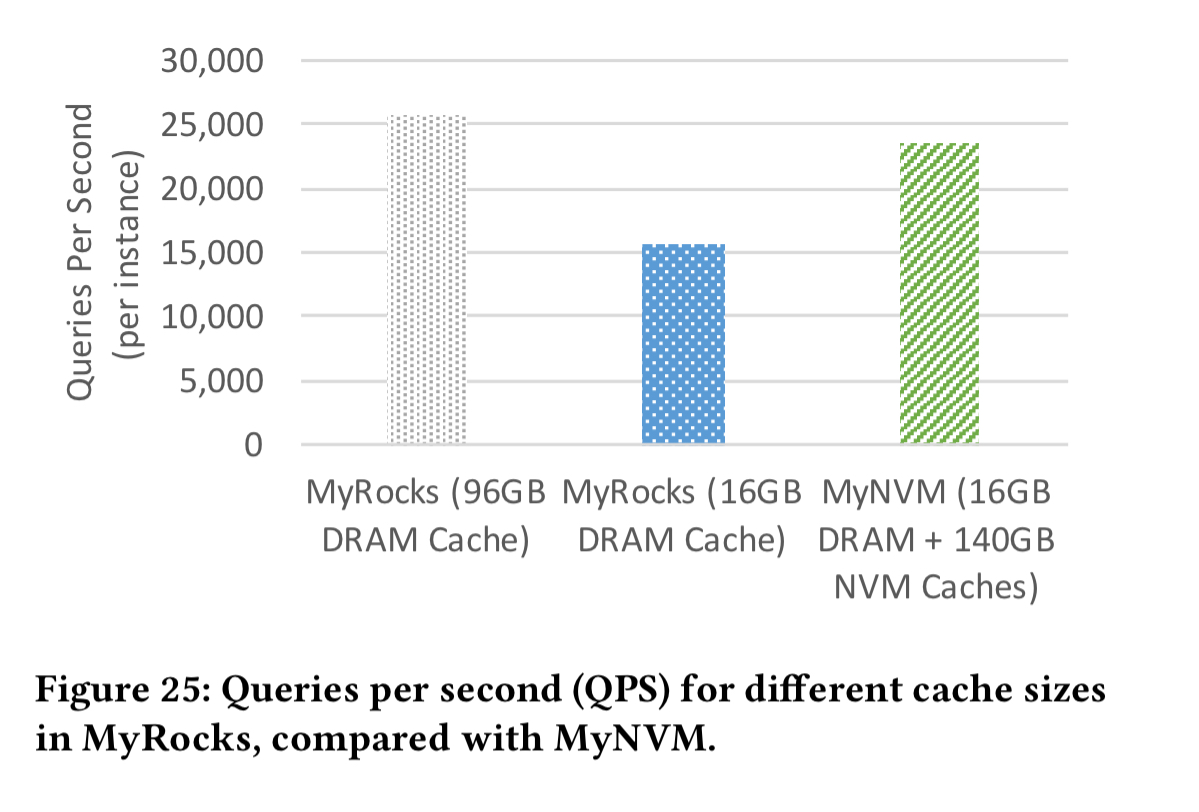
The following chart shows the results achieved in production when replacing RocksDB with MyNVM as the storage engine inside MyRocks. Comparing the first and third data points, you can see that MyRocks/MyNVM has slightly higher latency (20% at P99) than MyRocks/RocksDB with 96GB storage, however it uses only 1/6th of the DRAM. MyRocks/MyNVM with 16GB of DRAM is 45% faster than MyRocks/RocksDB also with 16GB DRAM. So the NVM layer is doing a good job of reducing costs while closing the performance gap.
NVM comes in two form factors: byte-addressable DIMM, and also as a block device. Much of the prior work focuses on the DIMM use case. But Facebook use the block device form factor due to its lower cost. As we’ll see shortly, loading data in blocks has knock-on effects all the way through the design.
Tricky things about NVM
NVM is less expensive than DRAM on a per-byte basis, and is an order-of-magnitude faster than flash, which makes it attractive as a second level storage tier. However, there are several attributes of NVM that make it challenging when used as a drop-in replacement for DRAM, namely its higher latency, lower bandwidth, and endurance.
Facebook swap 80GB of DRAM for 140GB of NVM. The lower latency of NVM is therefore compensated for by the higher hit rate from having a larger cache. However, bandwidth becomes a bottleneck. Peak read bandwidth with NVM is about 2.2GB/s, which is 35x lower than DRAM read bandwidth. This issue is made worse by the fact that Facebook chose to use NVM as a block device, so data can only be read at a granularity of 4KB pages. For small objects, this can result in large read amplification.
… we found the NVM’s limited read bandwidth to be the most important inhibiting factor in the adoption of NVM for key-value stores.
NVM also has endurance considerations: if cells are written to more than a certain number of times they wear out and the device lifetime is shortened. In the cache use case with frequent evictions this can easily become a problem, so NVM can’t be used as a straight drop-in replacement for DRAM without some care taken to avoid excessive writes.
Finally, given the very low latency of NVM compared to other block devices, the operating system interrupt overhead itself becomes significant (about 2µs out of a 10µs average end-to-end read latency).
The design of MyNVM
MyNVM uses NVM as a 2nd level write-through cache. The objective is to significantly reduce costs while maintaining latency and qps.
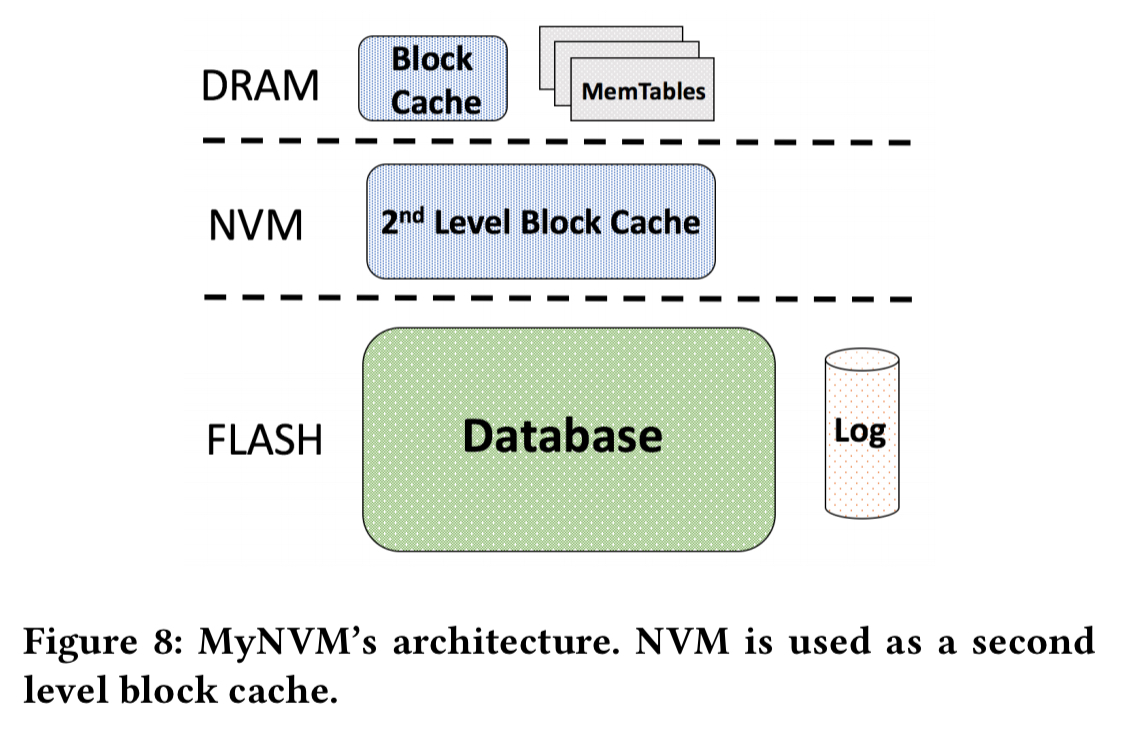
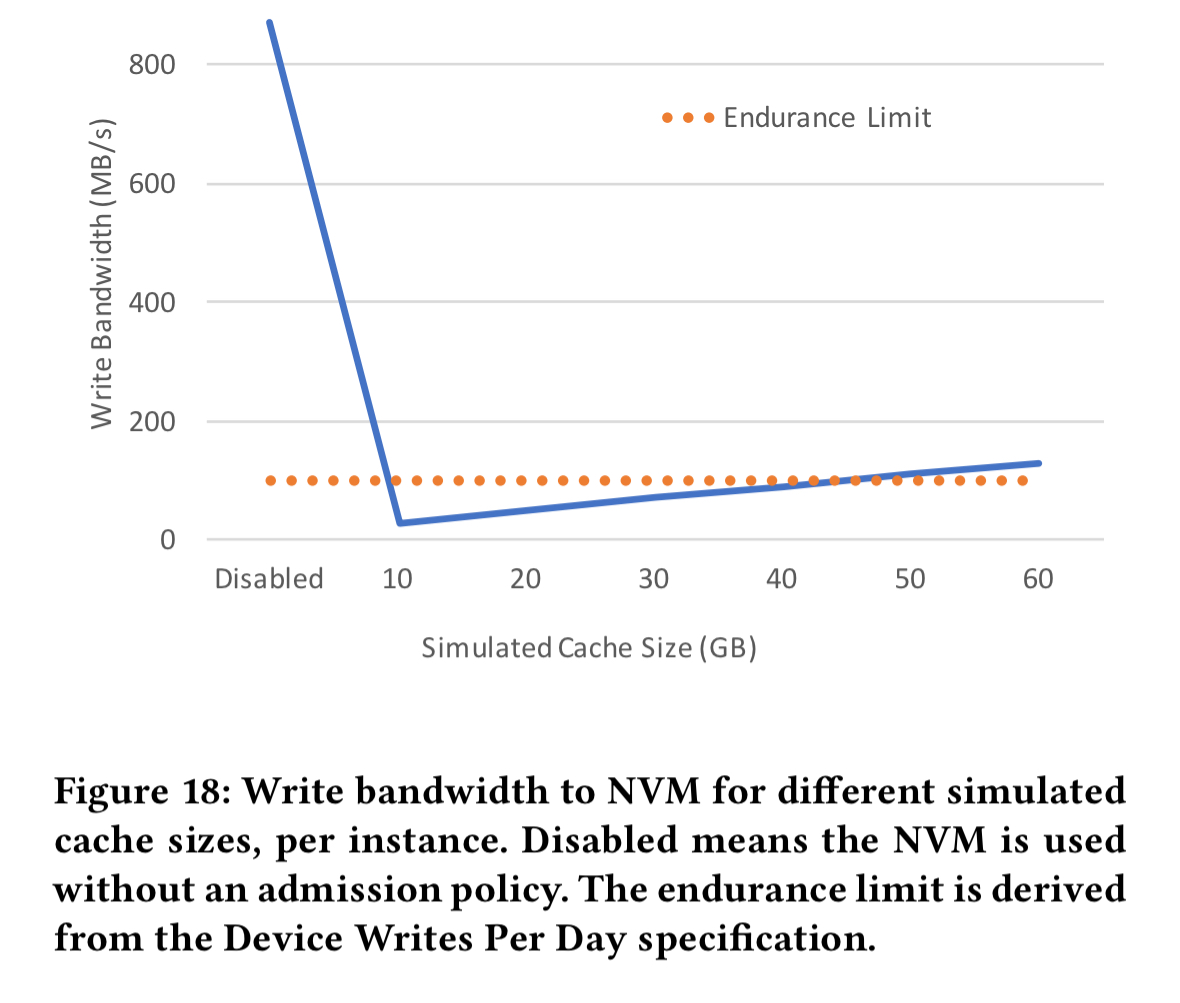
The default block size is 16KB, which means fetching at least 16KB every time we want to read an object. This ends up requiring more than double the available read bandwidth. Reducing the block size to 4KB actually makes things worse! This is due to the increased footprint of the DRAM index blocks (4x), which in turn lower the available DRAM for caching, and hence increase the hit rate on the 2nd level NVM cache.

To address this problem, the index is itself partitioned into smaller blocks, with an additional top-level index. Only the top-level index and the relevant index partitions then need to to read and cached in DRAM for any given lookup. This brings the required read bandwidth down, but as shown in the figure above, we’re still right up against the device limits.

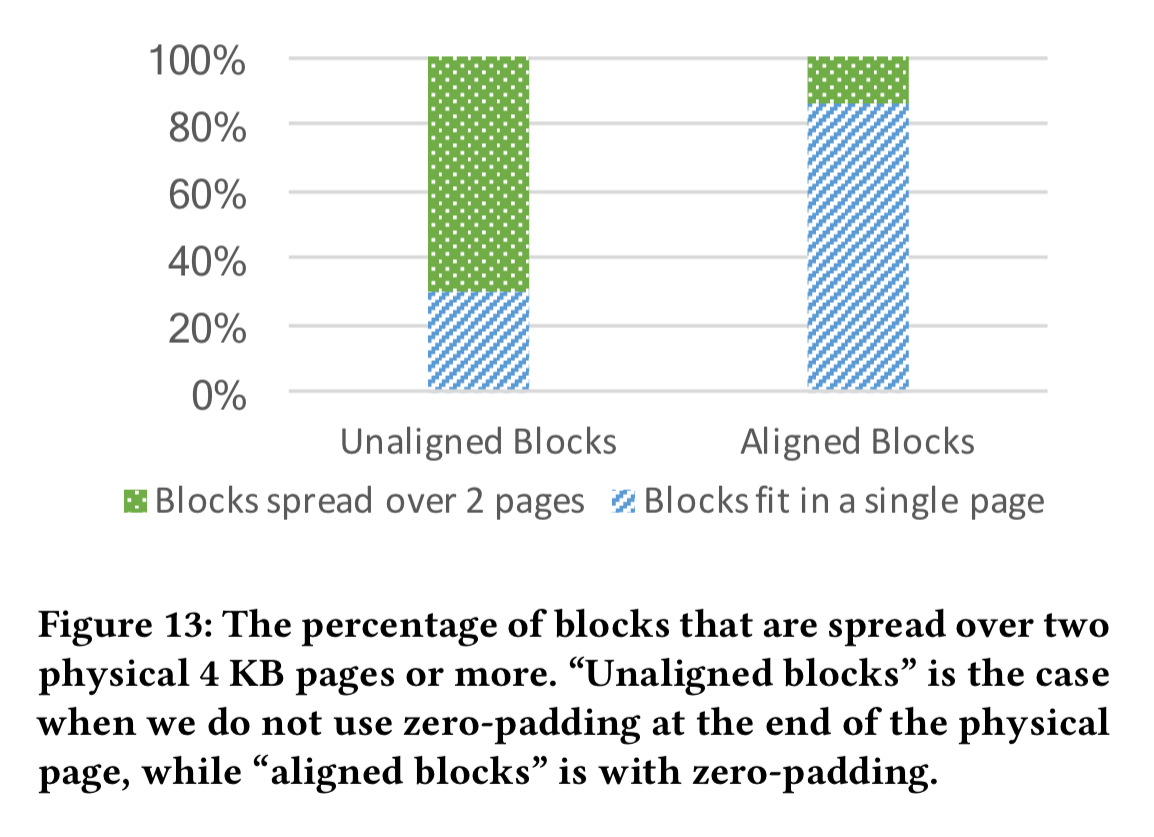
We can further reduce the read bandwidth requirement by carefully aligning blocks with physical pages. RocksDB data blocks are compressed by default, so that a 4KB block consumes less than that when compressed and written to NVM. Now we end up in a situation where data blocks span pages, and we may need to read two pages for a single block. MyNVM elects to use 6KB blocks, which compress on average to 4KB. (As a nice side-effect, this also reduces the size of the index). The 6KB blocks compress to around 4KB, but still don’t align perfectly with pages. MyNVM zero pads the end of a page if the next compressed block cannot fully fit into the same page. This reduces the number of blocks spread over two pages by about 5x.
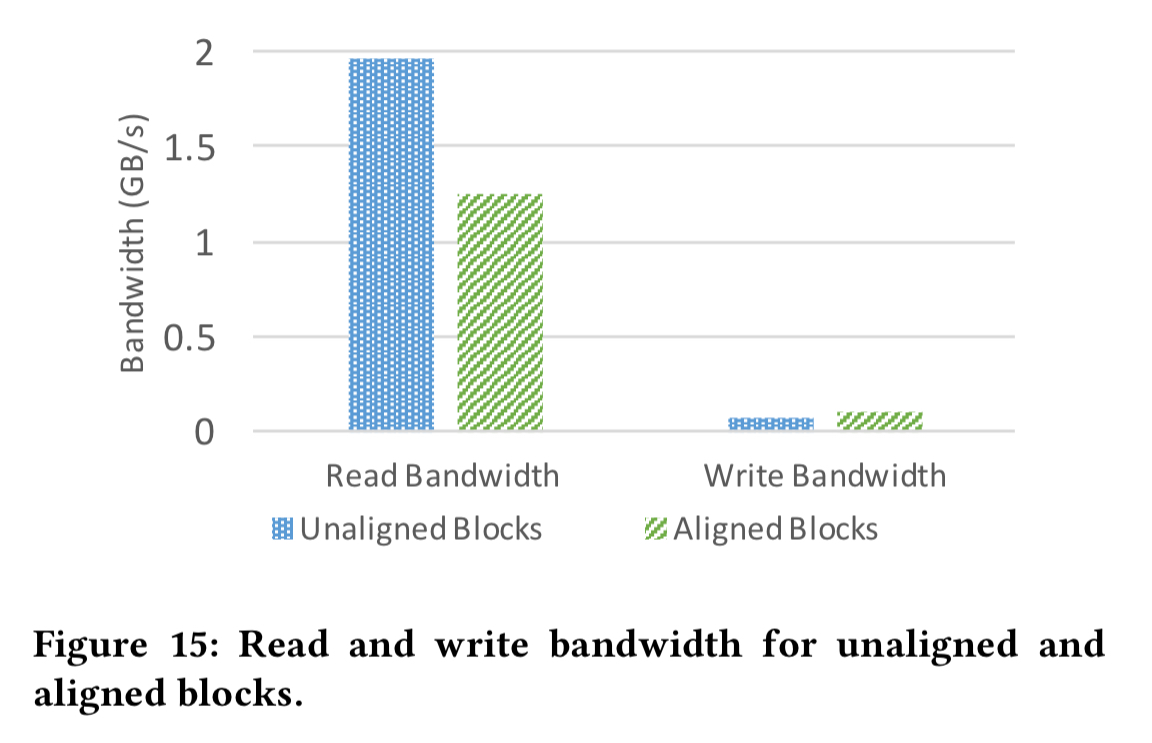
The improved block alignment buys a lot more read bandwidth headroom:
It also reduces the P99 latency since we’re reading less data.
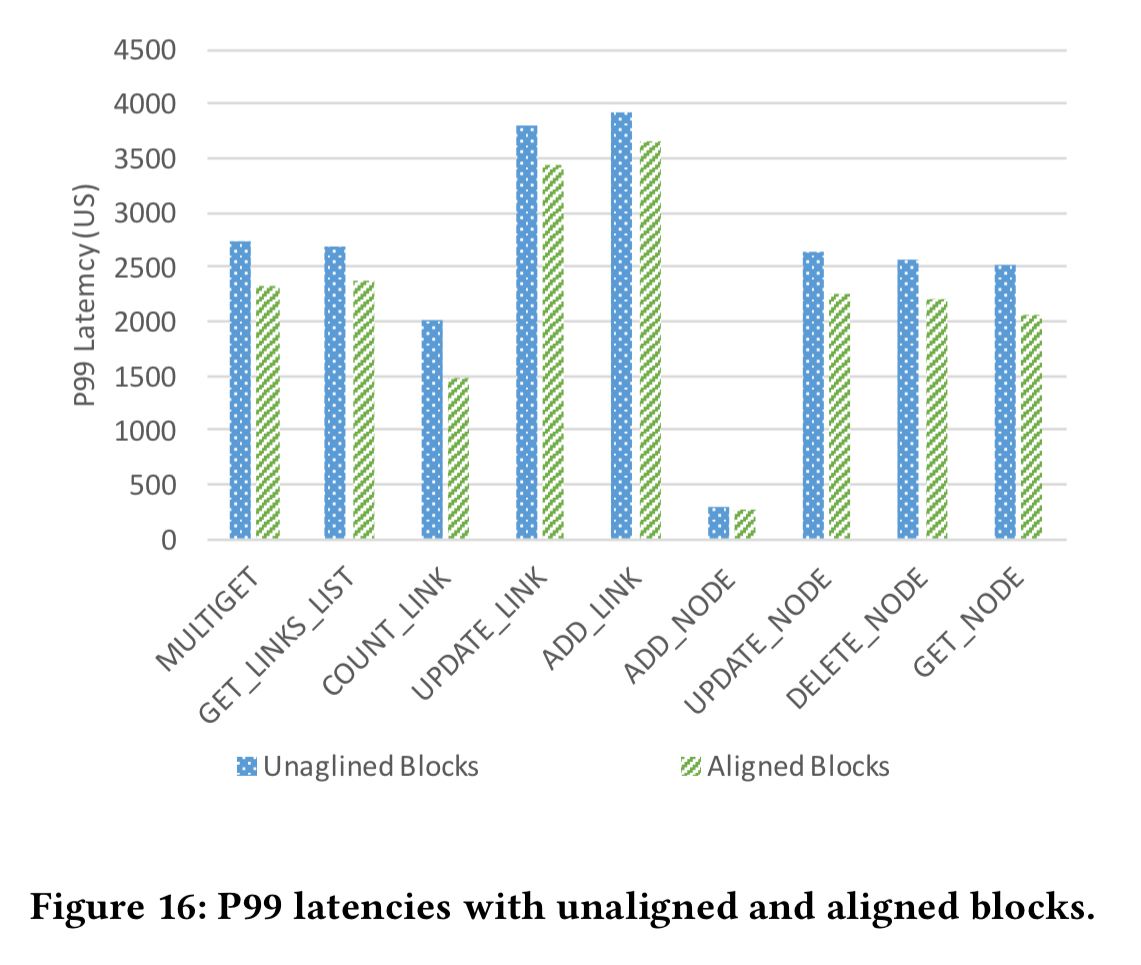
By default RocksDB applies compression using a per-block dictionary. With smaller block sizes this makes the compression less effective (11% overhead at 6KB blocks). To combat this, MyNVM using a preloaded dictionary based on data uniformly sampled across multiple blocks. This reduces the overhead to 1.5%.
Addressing the durability constraint
To avoid wearing out the NVM, MyNVM uses an admission control policy to only store blocks in the 2nd level cache that are not likely to be quickly evicted. An LRU list is kept in DRAM representing the size of the NVM. When a block is allocated from flash it is only cached in NVM if it has been recently accessed and is therefore present in the simulated cache LRU. For MyNVM, using a simulated cache size of 40GB gives sufficiently accurate prediction to accommodate the endurance limitation of the device.
Interrupt latency
To lower the operating system interrupt overhead, the team explored switching to a polling model. Continuous polling quickly took CPU usage of a core to 100%. A hybrid polling strategy involving sleeping for a time threshold after an I/O is issue before starting to poll significantly reduced the CPU usage again. With 8 threads or more though, the benefits of polling diminish.
An improved polling mechanism in the kernel could remove many of these limitations. Until that is available, we decided to currently not integrate polling in our production implementation of MyNVM, but plan to incorporate it in future work.
Evaluation
We saw the headline production results at the top of this post. The following figures show the mean and P99 latencies achieved over a 24 hour period, with intervals of 5M queries.
And here we can see the queries per second comparison:
This is just the beginning
NVM can be utilized in many other data center use cases beyond the one described in this paper. For example, since key-value caches, such as memcached and Redis, are typically accessed over the network, their data can be stored on NVM rather than DRAM without incurring a large performance cost. Furthermore, since NVM is persistent, a node does not need to be warmed up in case it reboots. In addition, NVM can be deployed to augment DRAM in a variety of other databases.