ForkBase: an efficient storage engine for blockchain and forkable applications Wang et al., arXiv’18
ForkBase is a data storage system designed to support applications that need a combination of data versioning, forking, and tamper proofing. The prime example being blockchain systems, but this could also include collaborative applications such as GoogleDocs. Today for example Ethereum and HyperLedger build their data structures directly on top of a key-value store. ForkBase seeks to push these properties down into the storage layer instead:
One direct benefit is that it reduces development efforts for applications requiring any combination of these features. Another benefit is that it helps applications generalize better by providing additional features, such as efficient historical queries, at no extra cost. Finally, the storage engine can exploit performance optimization that is hard to achieve at the application layer.
Essentially what we end up with is a key-value store with native support for versioning, forking, and tamper evidence, built on top of an underlying object storage system. At the core of ForkBase is a novel index structure called a POS-Tree (pattern-oriented-split tree).
The ForkBase stack
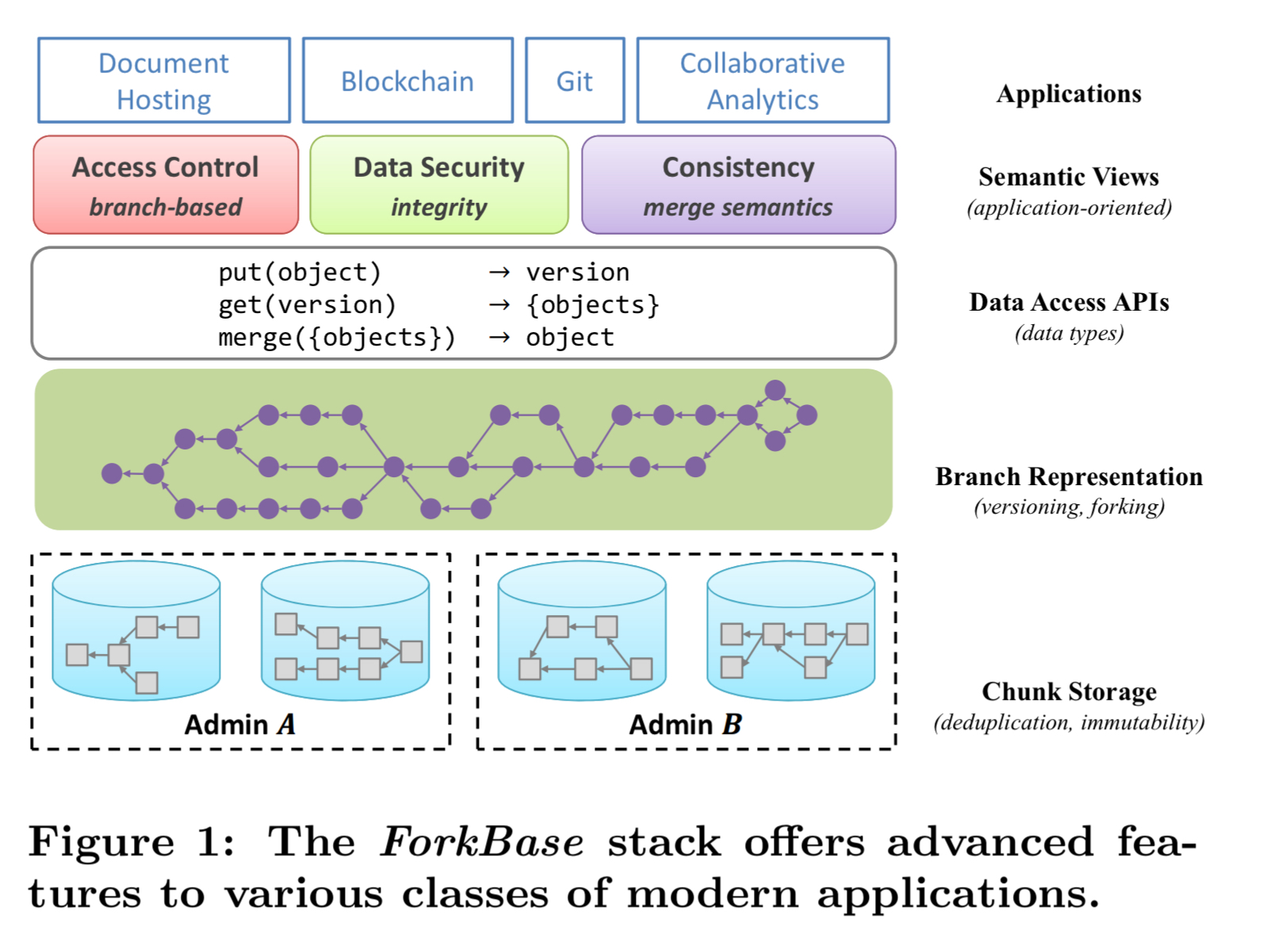
From the bottom-up, ForkBase comprises a chunk storage layer that performs chunking and deduplication, a representation layer that manages versions, branches, and tamper-proofing, and a collection of data access APIs that combine structured data types and fork semantics. Higher level application services such as access control and custom merge functions can be implemented on top of the API.
ForkBase is a key-value store, where the stored objects are instances of FObject.

Data versioning
The main challenge with data versioning (keeping the full history of every data item, including any branches and merges) is managing storage consumption. Clearly there is an opportunity for deduplication, on the assumption that versions do not completely change their content from one version to the next.
Delta-based deduplication stores just the differences (deltas) between versions, and reconstructs a given version by following a chain of deltas. You can play with the storage/reconstruction cost trade-off in such schemes.
Content-based deduplication splits data into chunks, each of which is uniquely identified by its content (i.e., a hash of the content). Identical data chunks can then be detected and redundant copies eliminated.
ForkBase opts for content-based deduplication at the chunk level. Compared to similar techniques used in file systems, ForkBase uses smaller chunks, and a data-structure aware chunking strategy. For example, a list will only be split at an element boundary so that a list item never needs to be reconstructed from multiple chunks. ForkBase recognises a number of different chunk types, each uniquely identified by its cid, which is simply a hash of the chunk contents.
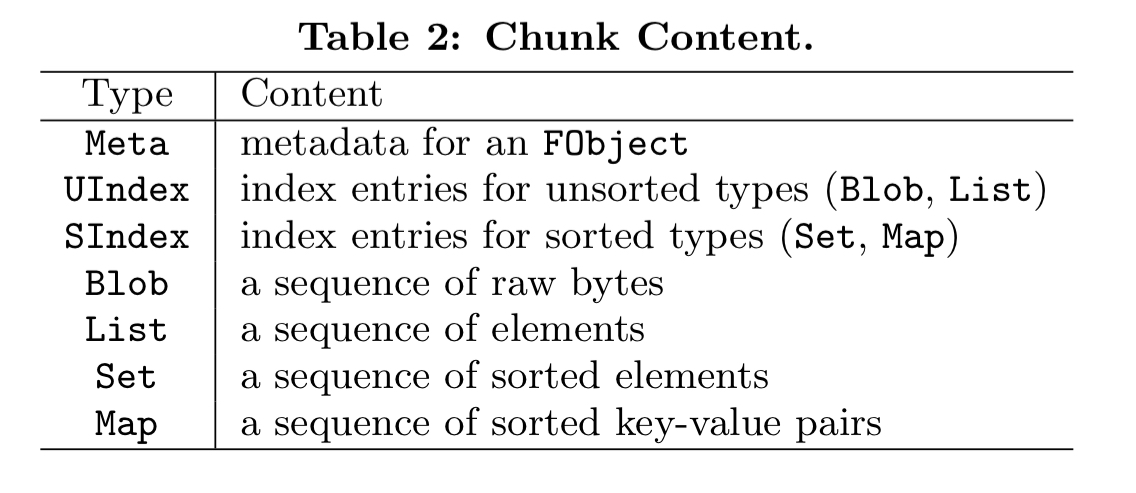
The chunkable object types (Blob, List, Set, and Map) are stored as POS-Trees, which will look at shortly.
A FObject’s uid is simply an alias for the chunk id of the Meta chunk for the object.
Fork semantics
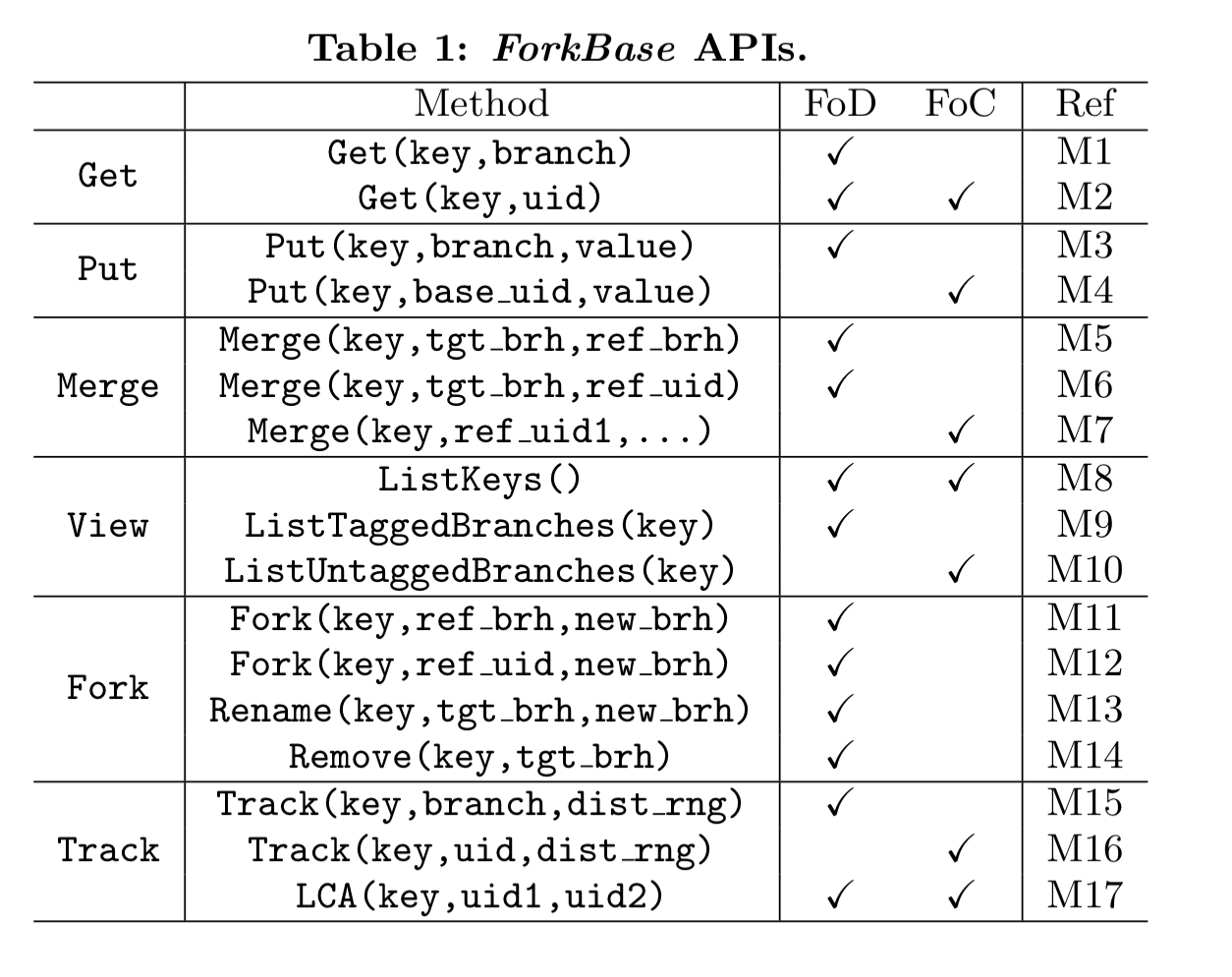
Support for forking is based in two key operations: forking and conflict resolution. Fork operations create a new branch, which evolves independently with local modifications isolated from other branches. ForkBase supports both on-demand and on-conflict forking.
On-demand forks are explicitly requested via the API and are tagged with a user-supplied name. An on-conflict fork is implicitly created upon concurrent modification of the same data item. A branch created as a result of a Fork-on-Conflict is untagged, and is identified simply by its uid.
Tagged branches can be merged with another branch, identified either by tag or by version. When conflicts are detected during a merge a conflict list is returned and the application layer is asked to provide a resolution. There are built-in resolution functions for simple strategies such as append, aggregate, and choose-one.
Tamper evidence
The uid of an FObject uniquely identifies both the object’s value and its derivation history. Logical equivalence therefore requires objects have not only the same value, but also the same history. Versions are linked in a cryptographic hash chain to to ensure any attempt at tampering can be detected. Each FObject stores the hashes of the previous versions it derives from in the bases field.
The Pattern-Oriented-Split Tree
Large structured objects are not usually accessed in their entirety. Instead, they require fine-grained access, such as element look-up, range query and update. These access patterns require index-structures e.g., B+-tree, to be efficient. However, existing index structures are not suitable in our context that has many versions and where versions can be merged.
The capacity-based splitting strategies of B+-trees and variants are sensitive to the values being indexed and their insertion order. This makes it harder to deduplicate across versions, and harder to find differences between two versions when merging. Using fixed-sized nodes gets around the insertion order issue, but introduces another issue known as the boundary-shifting problem due to the insertions in the middle of the structure.
The author’s solution is the Pattern-Oriented-Split Tree which supports the following properties:
- Fast lookup and update
- Fast determination of differences between two trees, and subsequent merge
- Efficient deduplication
- Tamper evidence
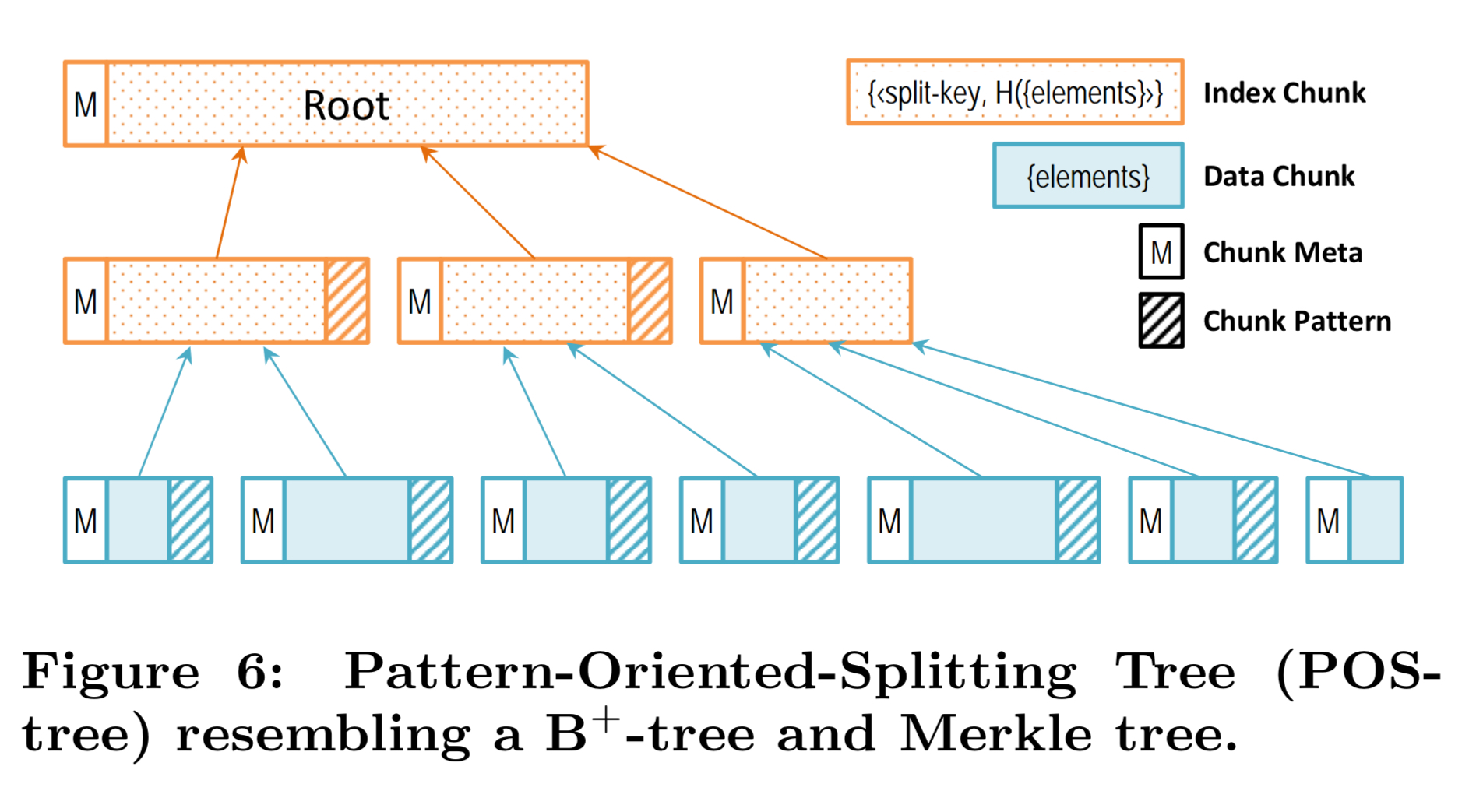
Every node in the tree is a chunk (either an index chunk, or at the leaves, an object chunk). Lookups follow a path guided by the split keys. Child node cids are crypographic hashes of their content, as in a Merkle tree. Two objects with the same data will have the same POS-tree, and tree comparison affords an efficient recursive solution. The real secret sauce here lies in how POS-Trees decide where to make splits.
The structure is inspired by content-based slicing and resembles a combination of a B+-tree and a Merkle tree. In a POS-tree, the node (i.e., chunk) boundary is defined as patterns detected from the object content. Specifically, to construct a node, we scan from the beginning until a pre-defined pattern occurs, and then create new node to hold the scanned content. Because the leaf nodes and internal nodes have different degrees of randomness, we define different patterns for them.
Leaf node splitting is done using a rolling hash function. Whenever the q least significant bits in the rolling hash are all zero a pattern match is said to occur. If a pattern match occurs in the middle of an element (e.g., a key-value pair in a Map) then the chunk boundary is extended to cover the whole element. Every leaf node except for the last node therefore ends with a pattern.
Index splitting uses a simpler strategy, looking for a cid pattern where cid && (2^r -1) == 0. The expected chunk size can be configured by choosing appropriate values for q and r. To ensure chunks cannot grow arbitrarily large, a chunk can be forced at some threshold value. POS-tree is not designed for cases the the object content is simply a sequence of repeated items – without the pattern all nodes gravitate to the maximum chunk size and the boundary shift problem returns.
ForkBase in action – Hyperledger
Section 5 of the paper looks at the construction of a blockchain platform, wiki engine, and collaborative analytics application on top of ForkBase. I’m just going to concentrate here on the blockchain use case, in which the authors port Hyperledger v0.6 to run on top of ForkBase.
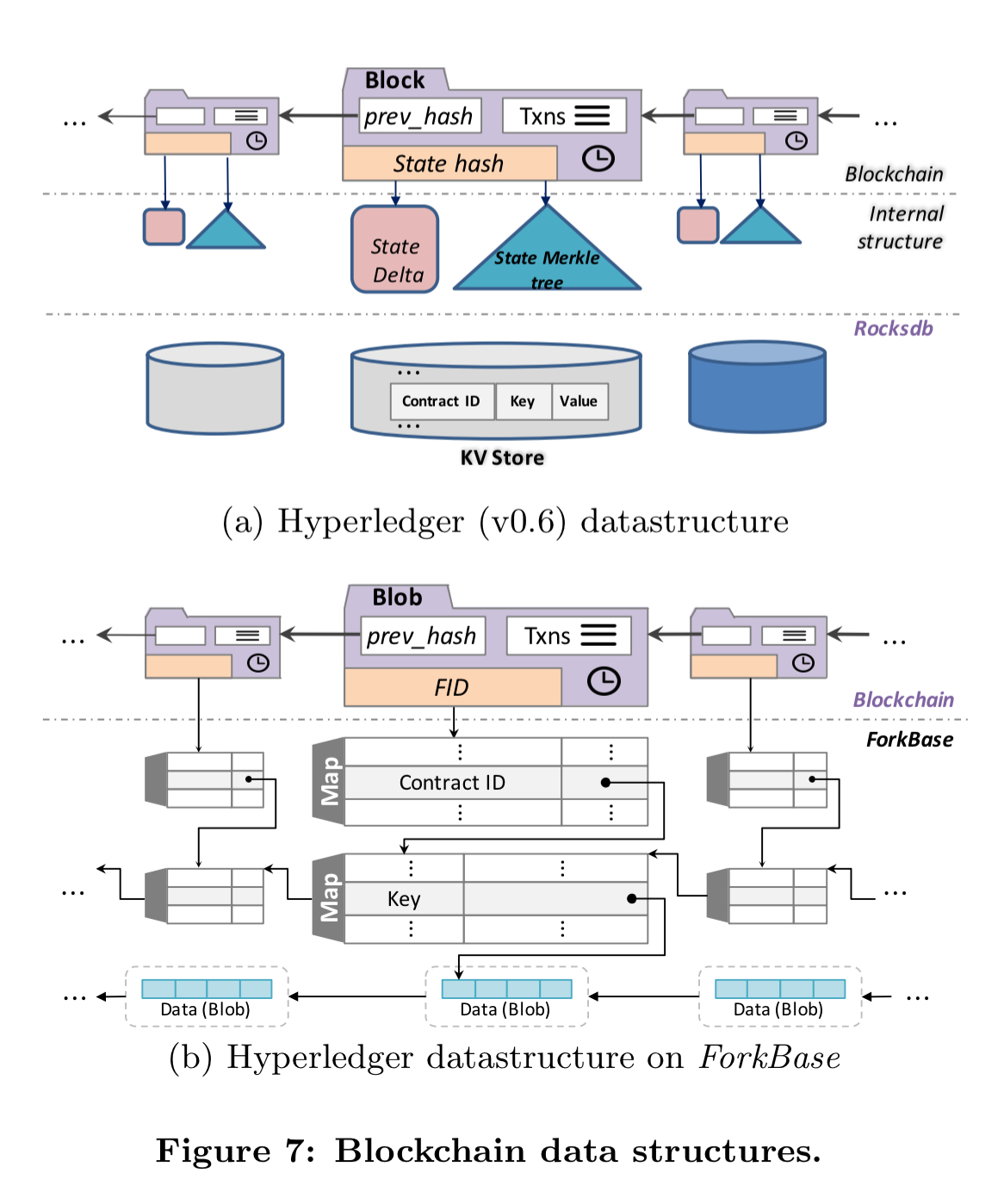
It takes 18 new lines of code to move Hyperledger on top of ForkBase, and the elimination of 1918 lines of code from the Hyperledger code base. (ForkBase itself is about 30K lines of code mind you!).
Another benefit is that the data is now readily usable for analytics. For state scan query, we simply follow the version number stored in the latest block to get the latest Blob object for the requested key. From there, we follow base-version to retrieve the previous values. For block scan query, we follow the version number stored on the requested block to retrieve the second-level Map object for this block. We then iterate through the key-value tuples and retrieve the corresponding Blob objects.
Both state scans (returning the history of a given state) and block scans (returning the values of the states at a specific block) are slower in the original Hyperledger codebase, which is designed for fast access to the latest states. (Note: this seems to be referring to the peer transaction manager, or PTM, component of HyperLedger. Hyperledger also includes a block store which is indexed).
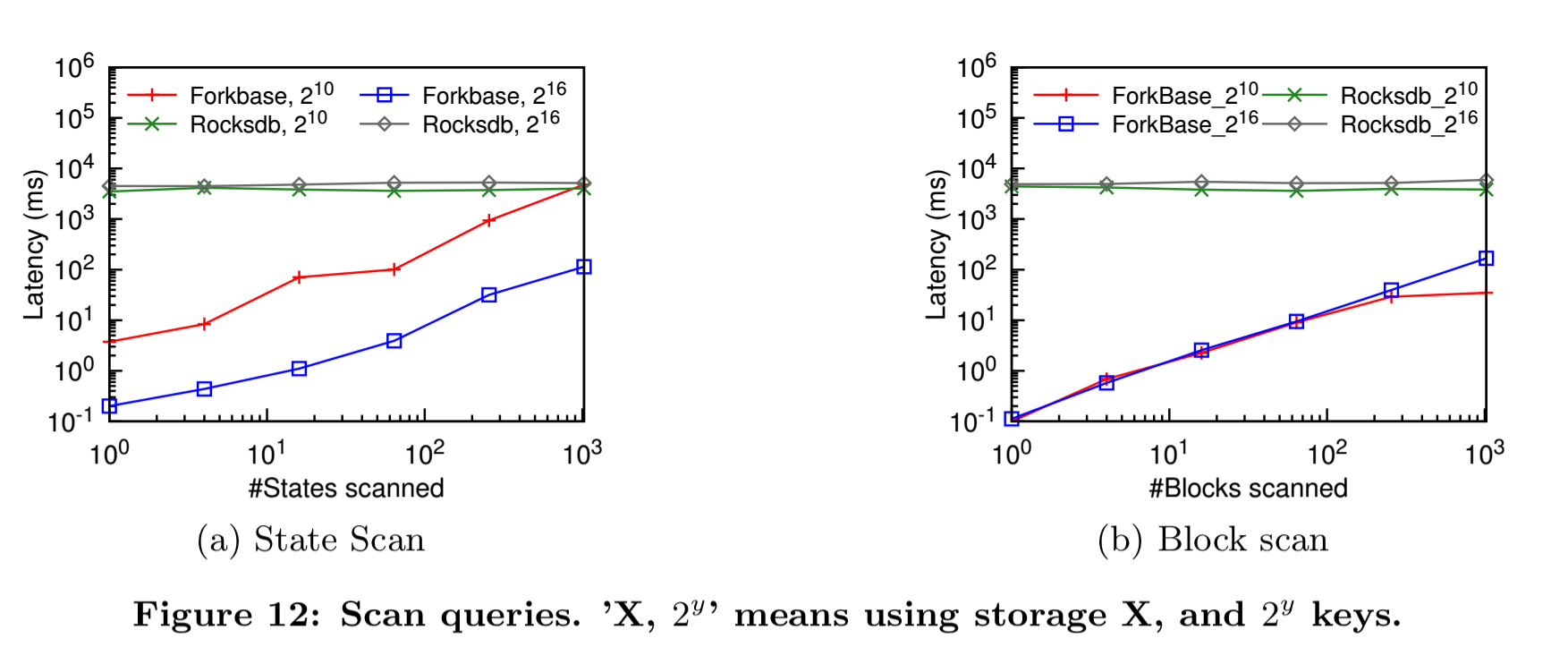
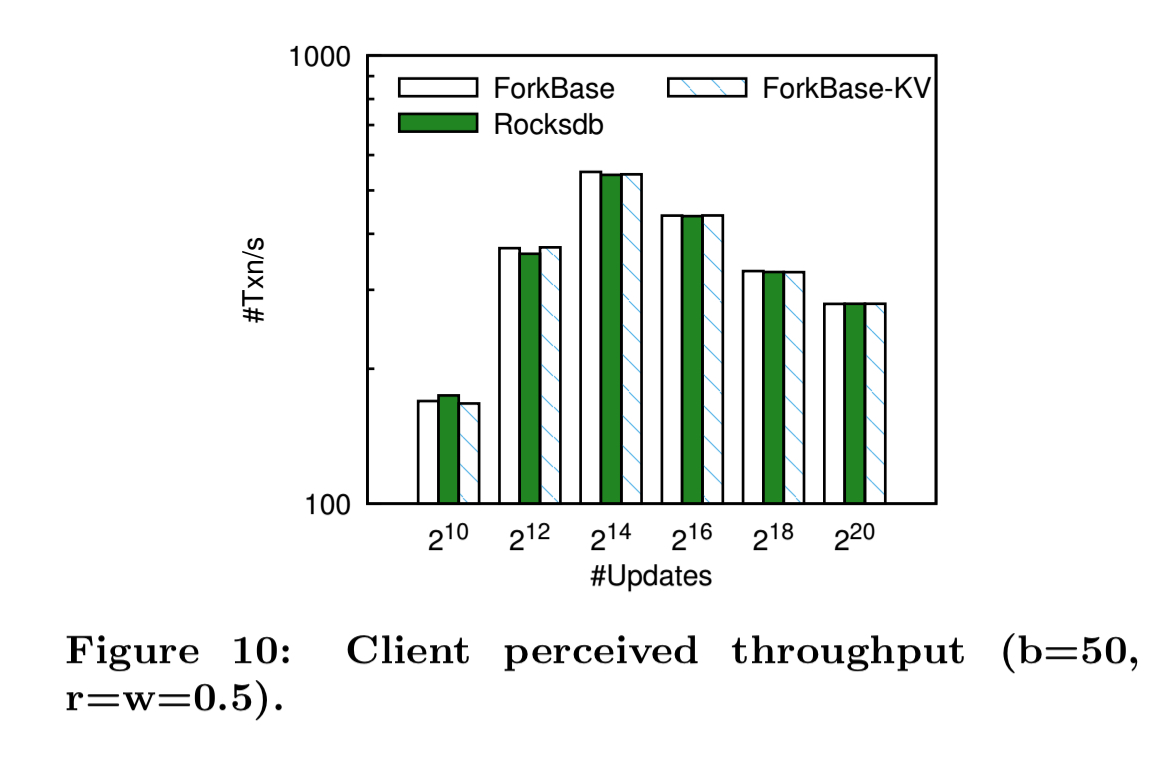
It’s in these scan operations that ForkBase shows the biggest performance benefits. If we look at latency and throughput, the ForkBase and Rocksdb based Hyperledger implementations are pretty close. (ForkBase-KV in the figure below is Hyperledger using ForkBase as a pure KV store, not taking advantage of any of the advanced features).
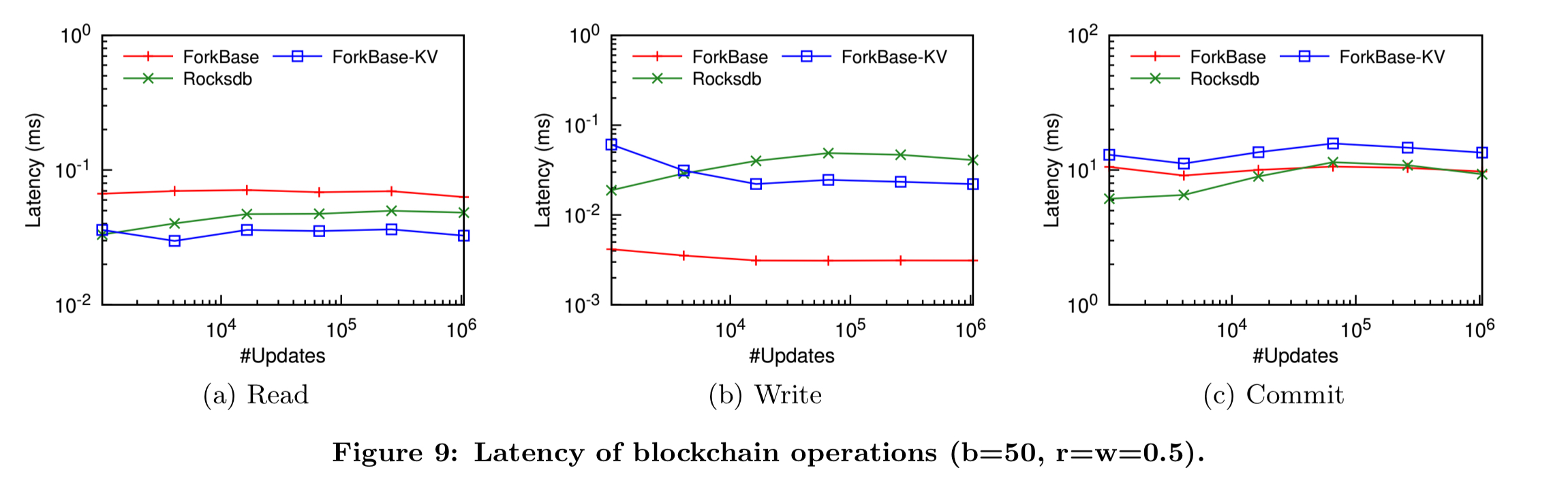
(Enlarge)
{kind=link}