Blockstack: a global naming and storage system secured by blockchains Ali et al., USENIX ATC’16
We’ll be back in the world of cryptocurrencies and blockchains for the rest of this week, kicking off with this 2016 paper on Blockstack. It’s interesting both for the lessons learned trying to build a system on top of the Namecoin blockchain, as well the subsequent design of Blockstack that was informed by those experiences. Blockstack itself has evolved since this 2016 paper (see the latest white paper) but the core ideas are all here.
A blockchain-based identity service
One good match for blockchain technology is as an immutable ledger securely binding names to values. Things you might ideally want in a naming system include human-readable names, a strong sense of ownership (name-value pairs can be owned by cryptographic keypairs), and no central trusted party. Zooko’s triangle suggested that you can’t have all three properties at once, but Namecoin showed that the combination is possible using a blockchain-based approach.
Namecoin itself was started to create an alternate DNS-like system that replaces DNS root servers with a blockchain for mapping domain names to DNS records.
Given that blockchains don’t have central points of trust, a blockchain-based DNS is much harder to censor and registered names cannot be seized from owners without getting access to their respective private keys.
Registration fees are required to prevent people from domain-squatting, but in Namecoin the recipient of the registration fees is a “black hole” cryptographic address from which money cannot be retrieved. Registration itself is a two-phase process in which a user first pre-orders a name hash, and then later registers the name-value pair by revealing the actual name and the associated value.
The authors of Blockstack wanted to create a Blockstack ID service along similar lines, which maps a name to public keys along with other profile data.
How (not to) build a decentralised PKI system
Namecoin has a d/ namespace used for domain names, and the first version of Blockstack ID was built on top of Namecoin using a new u/ namespace. After a year in production, a number of worries had started to surface around security, network reliability and throughput, selfish mining, the impact of hard forks, and the failure of merged mining. The authors distill this into five key lessons, with the following bottom line:
We strongly believe that decentralized applications and services need to be on the largest, most secure, and most actively maintained blockchain. Currently [2016] no other blockchain even comes close to Bitcoin in terms of these security requirements.
Lesson one: there is a fundamental tradeoff between blockchain security and introducing new functionality to blockchains.
Starting a new blockchain is always tempting, but new chains are significantly less secure than Bitcoin because of the much reduced mining activity.
The most important factor in the security of a blockchain is the total cost of attacking the blockchain and tampering with recently written data.
If a single miner (or pool) gets to 51% of the computational power mining on the chain, then all decentralised bets are off. In 2014, the authors noticed that a single mining pool consistently had more than 51% of the compute power on Namecoin, and it subsequently got worse with concentrations of power of up to 75% in a given week. “At such concentration, Namecoin is effectively controlled by a single party.”
Lesson two: there is currently a significant difference between the network reliability of the largest public blockchain network (Bitcoin) and network reliability of the long tail of alternate blockchains.
The authors noticed that some miners did indeed seem to be exploiting their concentrated power, either intentionally refusing or unable to package Blockstack transactions in their blocks. There were also cases of latency spikes caused by software issues in Namecoin itself.
Lesson three: selfish-mining is not just a theoretical attack, but selfish-mining like behaviour can already be observed in production blockchains.
Whenever software updates were issued on Namecoin, there was a considerable fluctuation of computing power: miners aren’t incentivised to upgrade software quickly for small chains which aren’t their main reason for operating a pool. This leads to…
Lesson four: Other than the engineering problems, consensus-breaking changes are complicated because of the fundamental incentive structures of the parties involved. System designers have never dealt with consensus-breaking changes before cryptocurrencies; it’s a novel challenge.
Finally, merged mining was supposed to address the problem of lesser mining power on smaller chains, by allowing Bitcoin miners to participate in the new network without spending extra compute cycles. Namecoin used merged mining with Bitcoin. “One of our key findings is that merged mining is currently failing in practice: the leading merged-mined blockchain, Namecoin, is vulnerable to the 51% attack.” This leads to lesson five:
Lesson five: At the current stage in the evolution of blockchains, there are not enough compute cycles dedicated to mining to support multiple secure blockchains.
After considering all of the above factors, it was an easy decision to move our PKI system from Namecoin to Bitcoin.
Blockstack v2: built on top of Bitcoin
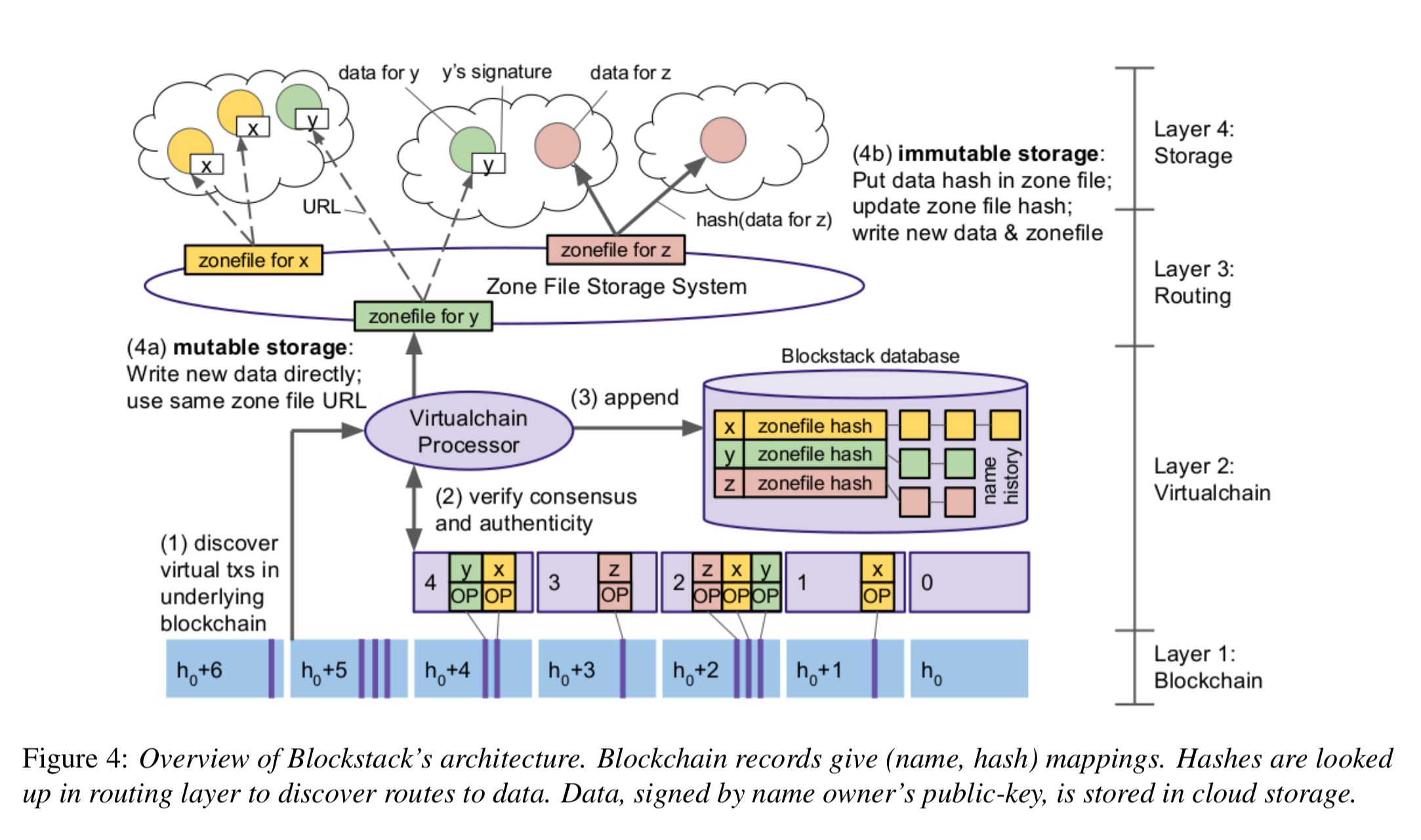
The most fundamental idea in Blockstack will be familiar to anyone with a background in networking: separate the control plane from the data plane. In particular, Blockstack keeps the control plane on the blockchain, and the data plane off the chain but anchored in an on-chain root of trust. This alleviates problems with data storage limits in blocks (the data isn’t on the chain, go ahead and store as much as you like!). You could actually use any underlying blockchain of your choosing, the deployment chooses Bitcoin.
Blockstack maintains a naming system as a separate logical layer on top of the underlying blockchain on which it operates. Blockstack uses the underlying blockchain to achieve consensus on the state of this naming system and bind names to data records. Specifically, it uses the underlying blockchain as a communication channel for announcing state changes, as any changes to the state of name-value pairs can only be announced in new blockchain blocks.
(Enlarge)
{kind=link}
The control plane comprises the underlying blockchain itself, and a logically separate “virtualchain” built on top of it. The data plane handles data storage and availability with a routing layer that tells you where to find things, and a storage layer that looks after the data itself.
The Virtualchain layer
A key contribution of Blockstack is the introduction of a logically separate layer on top of a blockchain that can construct an arbitrary state machine after processing information from the underlying blockchain. We call this layer a virtualchain. A virtualchain treats transactions from the underlying blockchain as inputs to the state machine and valid inputs trigger state changes. At any given time, where time is defined by the block number, the state machine can be in exactly one global state.
You could also a state machine like this using a smart contract. The paper doesn’t explicitly discuss why that option was rejected, but I can see two arguments: firstly, that would restrict the choice of underlying chain, and rule out the Bitcoin blockchain; and secondly, depending on design parameters, the state within the state machine may get too large to easily store on chain. The 2017 Blockstack white paper does touch on this issue, additionally saying, “Nodes on the network should not be required to compute complex untrusted programs just to stay synced with the network.”
Only Blockstack nodes are aware of the virtualchain layer, and blockstack operations are encoded in valid blockchain transactions as additional metadata. The virtualchain idea is independent of the actual state machine you use it with, Blockstack defines a global naming and storage system state machine. Here are the states and transitions for the naming system state machine:
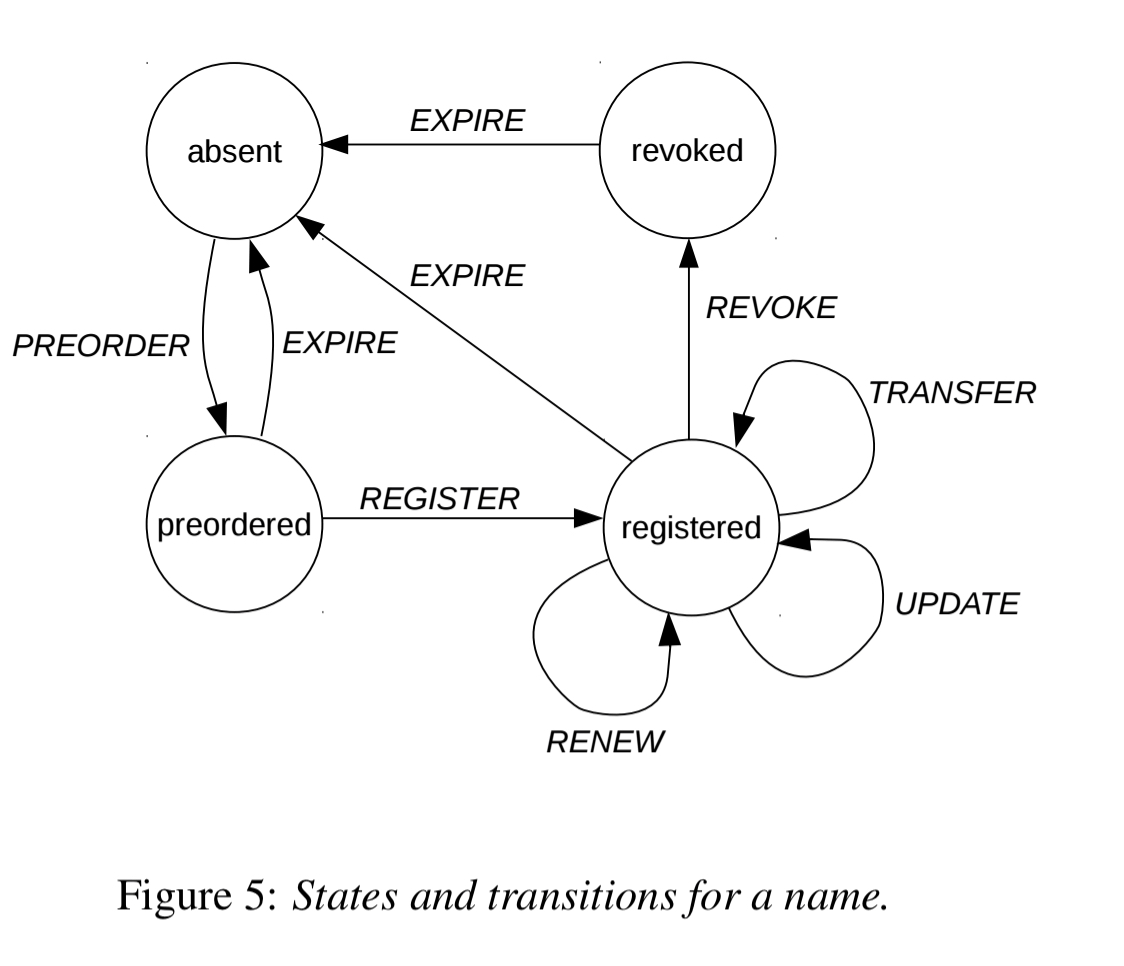
What I can’t easily tell from the paper, is how I know I can trust the state machine logic. It’s not on the underlying blockchain (as it would be with a smart contract), so presumably it’s just embodied in code running on Blockstack nodes. If it essentially becomes impossible to upgrade those nodes without everyone noticing, and the code is open source, I guess that arguably gives similar properties to a smart contract. The second part of the answer here is you don’t necessarily need to inspect and validate the logic of the state machine, so long as you can validate the resulting state (i.e., the state is all that matters). Drawing again from the 2017 white paper on this topic:
Application nodes replay their logs to achieve application level consensus at each block b, such that two nodes will agree on a block if and only if the application transactions in that block leave the nodes in an identical state. If their resulting state after executing the operations in block b are identical, then their generated consensus hash for that block will be the same. Consensus hashes enable nodes to independently audit and efficiently query their histories, as well as detect forks and then migrate state between blockchains.
The routing layer
The task of routing requests is separated from the task of actually storing data. Blockstack uses zone files (c.f. DNS zone files) for storing routing information. The virtualchain binds names to their respective hash(zonefile) and stores these bindings in the control plane. The zone files themselves are stored in the routing layer.
Users do not need to trust the routing layer because the integrity of zone files can be verified by checking the hash(zonefile) in the control plane.
As of the time of writing the paper, nodes formed a DHT-based peer network for storing zone files. Only files whose hash has previously been announced on the chain will be stored. Blockstack today has migrated away from the DHT approach, and uses a new unstructured peer network called the Atlas network. All Atlas nodes maintain a 100% state replica and use gossip to keep up to date.
The storage layer
The storage layer hosts the actual data values for the name-value pairs. Stored values are signed by the key of the owner of the corresponding name.
By storing data values outside of the blockchain, Blockstack allows values of arbitrary size and allows for a variety of storage backends. Users do not need to trust the storage layer because they can verify the integrity of the data values in the control plane.
In mutable storage node, signed updates to the value can proceed as fast as the underlying storage system allows. There is a danger here though of readers consuming stale data. This problem is punted to the user: “readers and writers must employ a data versioning scheme to avoid reading stale data.” In immutable storage mode, a TXT record is also written in the zone file containing hash(data). Readers can verify data integrity by checking this hash. Throughput and latency for immutable writes is of course constrained by the underlying blockchain.
Blockstack today has implemented an overlay storage system called Gaia that sits on top of existing cloud storage providers.
Name verification
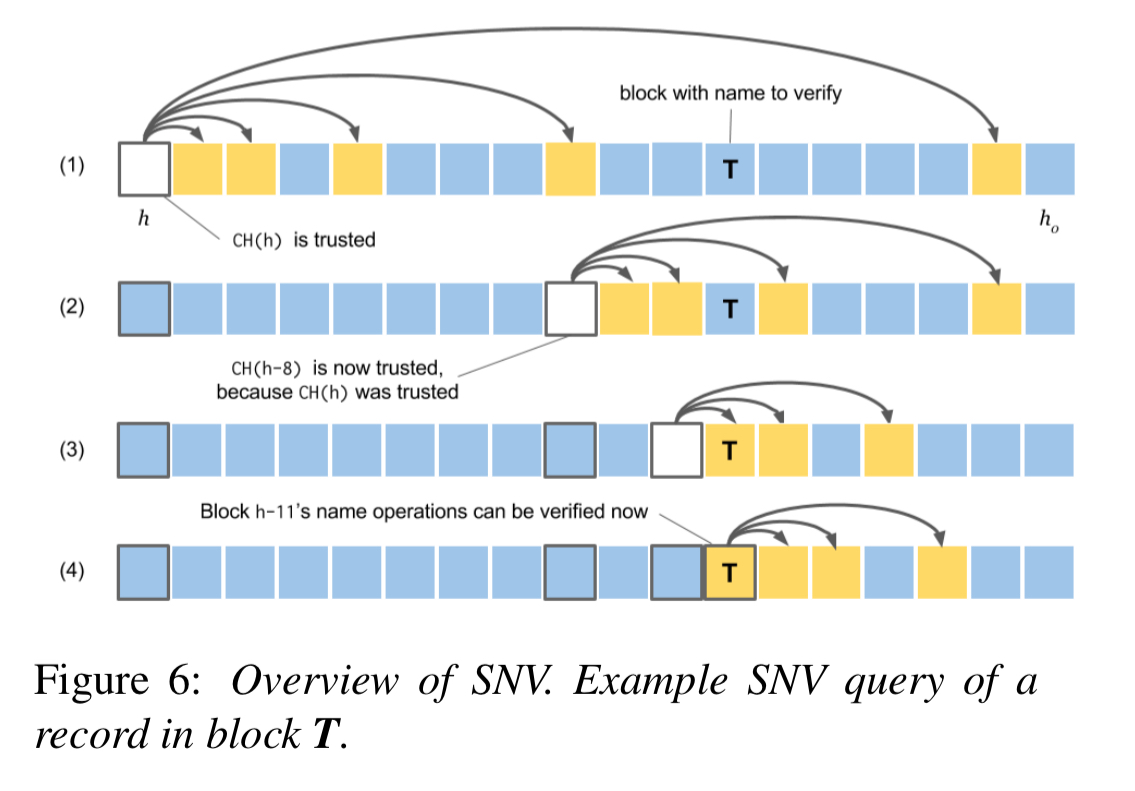
We briefly discussed the consensus hashes of state machine state in the virtualchain section. Consensus hashes also help new nodes come up to speed faster without needing to process the entire chain from block zero.
The process of verifying the authenticity of a prior name operation with a later trusted consensus hash is called Simplified Name Verification (SNV). SNV enables support for ‘thin clients,’ which can query the past state of the system without running Blockstack nodes or having access to the full blockchain history.
The construction of the consensus hash allows a user to verify the authenticity of any virtualchain operation from a block with height 
For the latest on blockstack, see https://blockstack.org.