Why neurons have thousands of synapses, a theory of sequence memory in neocortex Hawkins & Ahmad, Front. Neural Circuits 2016
It all began with a fascinating lunchtime conversation with Martin Thompson (@mjpt777), who mentioned to me a thought-provoking video he’d seen online from Jeff Hawkins regarding models of behaviour in the brain. A few days later I watched the video, then I bought the book “On Intelligence” and devoured it in one sitting. That book was written in 2004, and I was curious to learn of developments in the theory since. So we’re starting this week with a selection of three papers bringing the story up to date.
There’s also a link to the Turing Test that we finished up with last week. In the book, Hawkins stresses the central role of prediction in how our brain works, and ultimately therefore in what it means to be thinking:
Prediction is not just one of the things your brain does. It is the primary function of the neocortex, and the foundation of intelligence. The cortex is an organ of prediction. If we want to understand what intelligence is, what creativity is, how your brain works, and how to build intelligent machines, we must understand the nature of these predictions and how the cortex makes them. Even behavior is best understood as a by-product of prediction.
And:
We can now see where Alan Turing went wrong, prediction, not behavior, is the proof of intelligence…. the Turing Test, by equating intelligence with human behavior, limited our vision of what is possible.
Today’s paper choice looks at neurons in the brain, and the question of why they have so many excitatory synapses (thousands of them). Many of these aren’t modelled in the neural networks of machine learning. What do they do? And with that understanding, what would it look like to extend our neural network models to include a similar capability?
A neuron has a soma (cell body), an axon, and a network of dendrites . Synapses are the structures that pass signals between neurons. Synapses close to the cell body are called proximal. Those farther away are called distal. The activation of a distal synapse doesn’t seem to have much effect at the soma, so what are they for? If several distal synapses close to each other are activated together (an active dendrite), then a local spike can depolarise the soma.
A slightly depolarized cell fires earlier than it would otherwise if it subsequently receives sufficient feedforward input. By firing earlier it inhibits neighboring cells, creating highly sparse patterns of activity for correctly predicted inputs.
Neurons as pattern recognisers
It takes 8-20 close together synapses to activate at the same time, which then combine in a non-linear fashion, to trigger a dendritic spike.
Thus, a small set of neighboring synapses acts as a pattern detector. It follows that the thousands of synapses on a cell’s dendrites act as a set of independent pattern detectors. The detection of any of these patterns causes an NDMA spike and subsequent depolarisation at the soma.
When relatively few neurons are active relative to the population, then such pattern recognition is robust. That is, the chances of a false match become very low. By forming more synapses than the the minimum needed to trigger a spike, recognition also becomes robust to noise and variation. A single dendritic segment can contain several hundred synapses.
If we assume an average of 20 synapses are allocated to recognize each pattern, and that a neuron has 6000 synapses, then a cell would have the ability to recognize approximately 300 different patterns. This is a rough approximation, but makes evident that a neuron with active dendrites can learn to reliably recognize hundreds of patterns within a large population of cells.
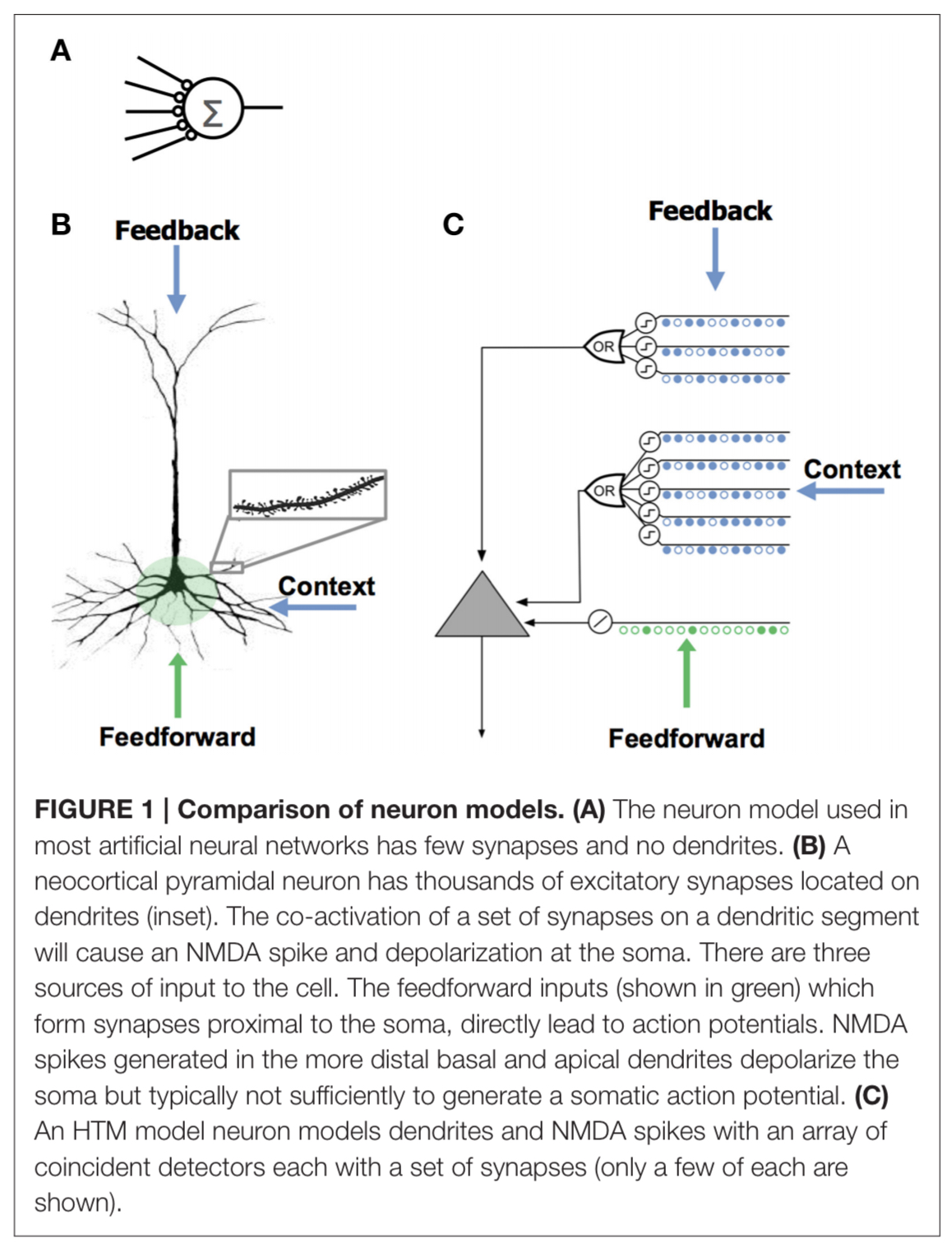
Neurons as predictors
Neurons receive input from different sources segregated on different parts of the dendritic tree. There are typical several hundred proximal synapses which receive feedforward input and have a relatively large effect at the soma, and define the basic receptive field response of the neuron. The basal synapses receive contextual input from nearly cells in the same cortical region, and apical synapses receive feedback input.
Spikes due to basal synapses activating depolarize the soma, but not enough to generate somatic action potential.
We propose that this sub-threshold depolarization is an important state of the cell. It represents a prediction that the cell will become active shortly and plays an important role in network behavior.
Apical synapses have a similar effect, and are used to establish a top-down expectation – which can be thought of as another form of prediction.
Learning sequences of patterns
Because all tissue in the neocortex consists of neurons with active dendrites and thousands of synapses, it suggests there are common network principles underlying everything the neocortex does. This leads to the question, what network property is so fundamental that it is a necessary component of sensory inference, prediction, language, and motor planning? We propose that the most fundamental operation of all neocortical tissue is learning and recalling sequences of patterns…
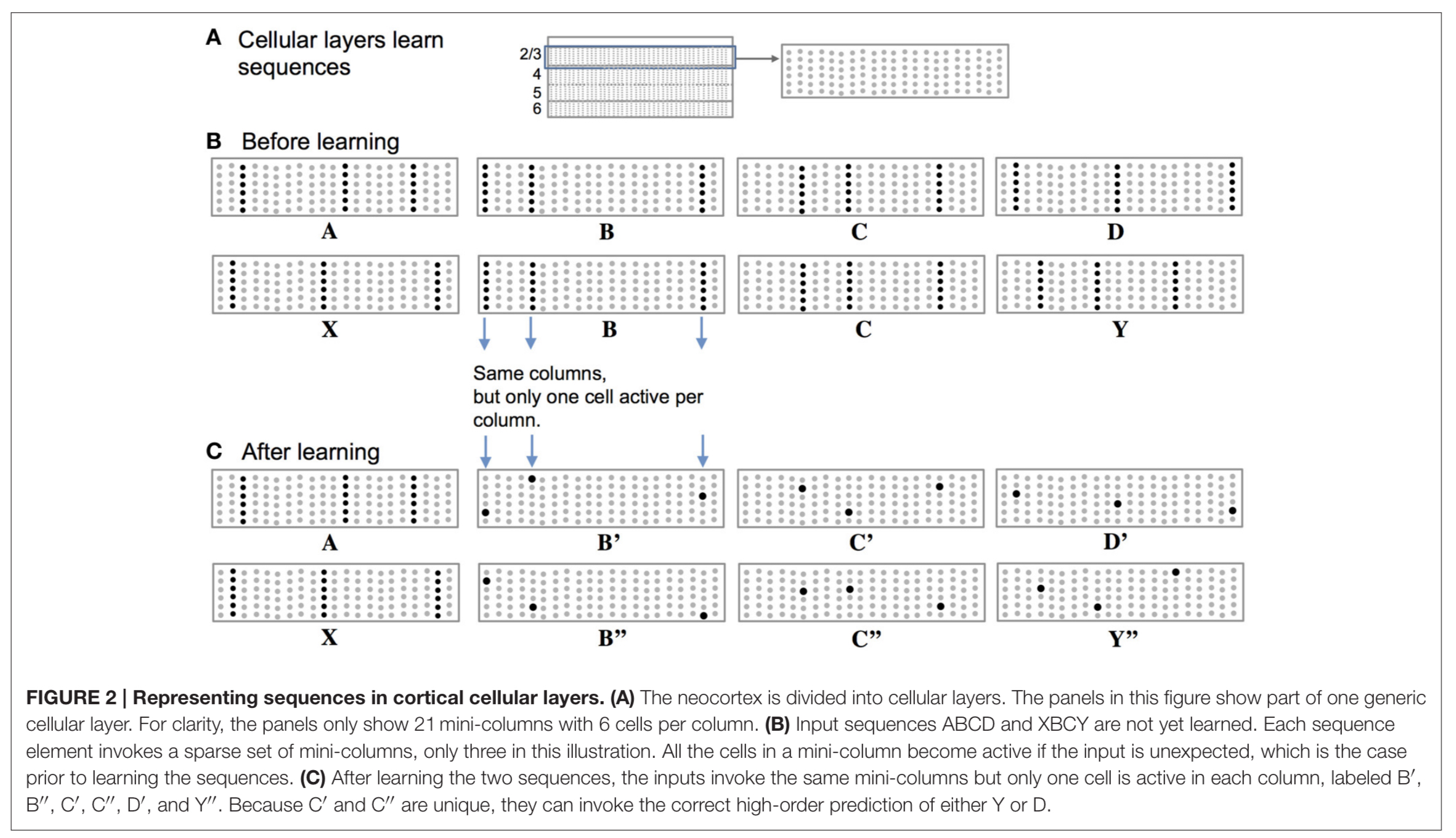
The neocortex is divided into cellular layers. Within layers we find mini-columns of cells. When an input is unexpected (i.e., it has not been predicted by pattern matching at the synapses leading to a spike and depolarisation) then all the cells in a column become active. This is the situation we find in (B) below when the sequences ‘ABCD’ and ‘XBCY’ have not yet been learned.
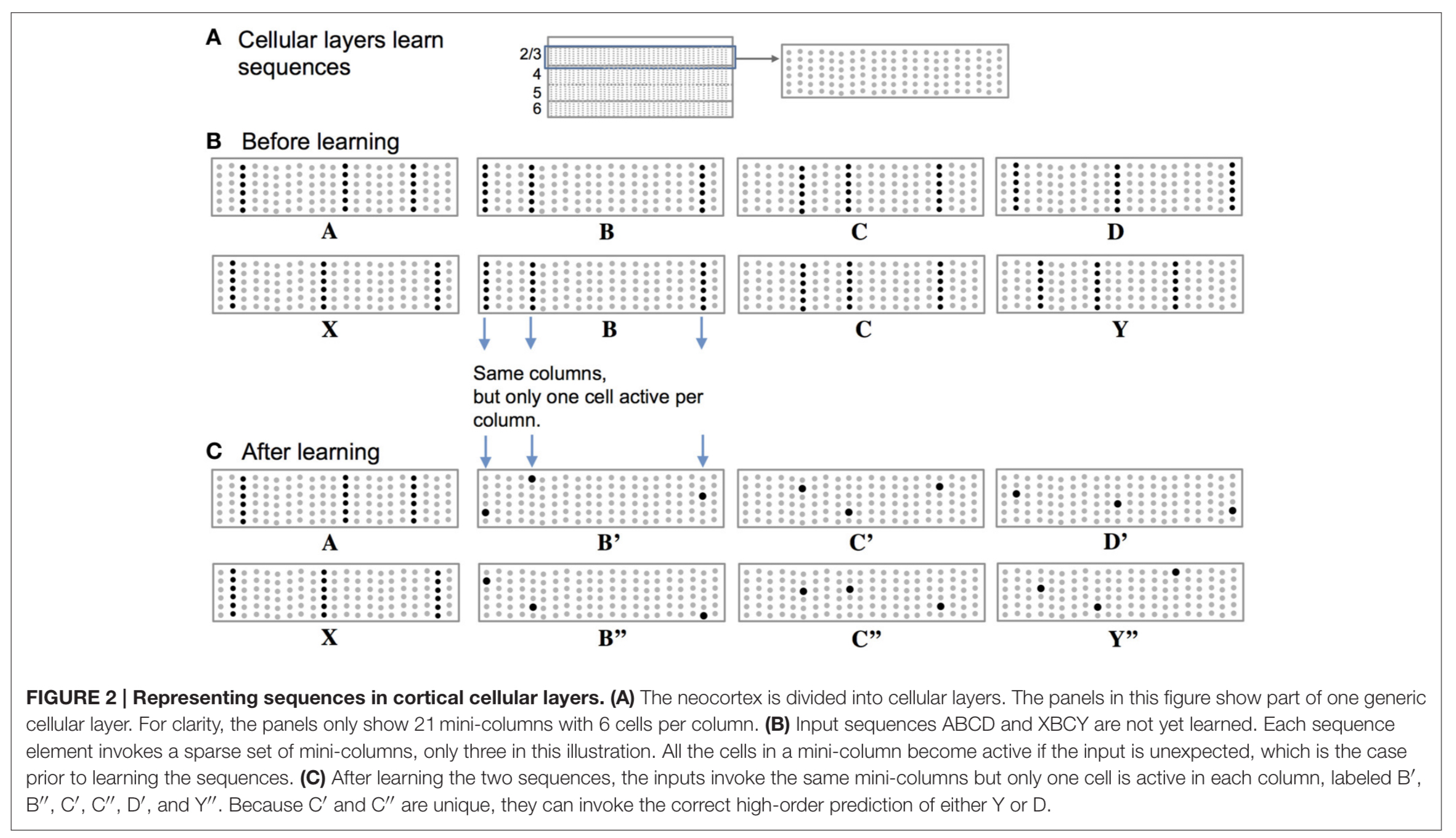
(Enlarge)
{kind=link}
After learning the sequences though, depolarised cells from the prediction of what should come next will fire first as they are ‘primed’, and this firing will inhibit the other cells nearby. ( (C) in the figure above).
Thus, a predicted input will lead to a very sparse pattern of cell activation that is unique to a particular element, at a particular location, in a particular sequence.
As feedforward input arrives it activates cells, while basal input is generating predictions. So long as the next input matches the current prediction, the sequence continues. The network may make multiple simultaneous predictions without confusion. If an input matches any of the predictions it will result in the correct highly sparse representation.
The apical dendrites connect neurons across layers 2, 3 and 5 in the neocortex. Their role seems to be to alert to deviations from expected sequences, as illustrated below.
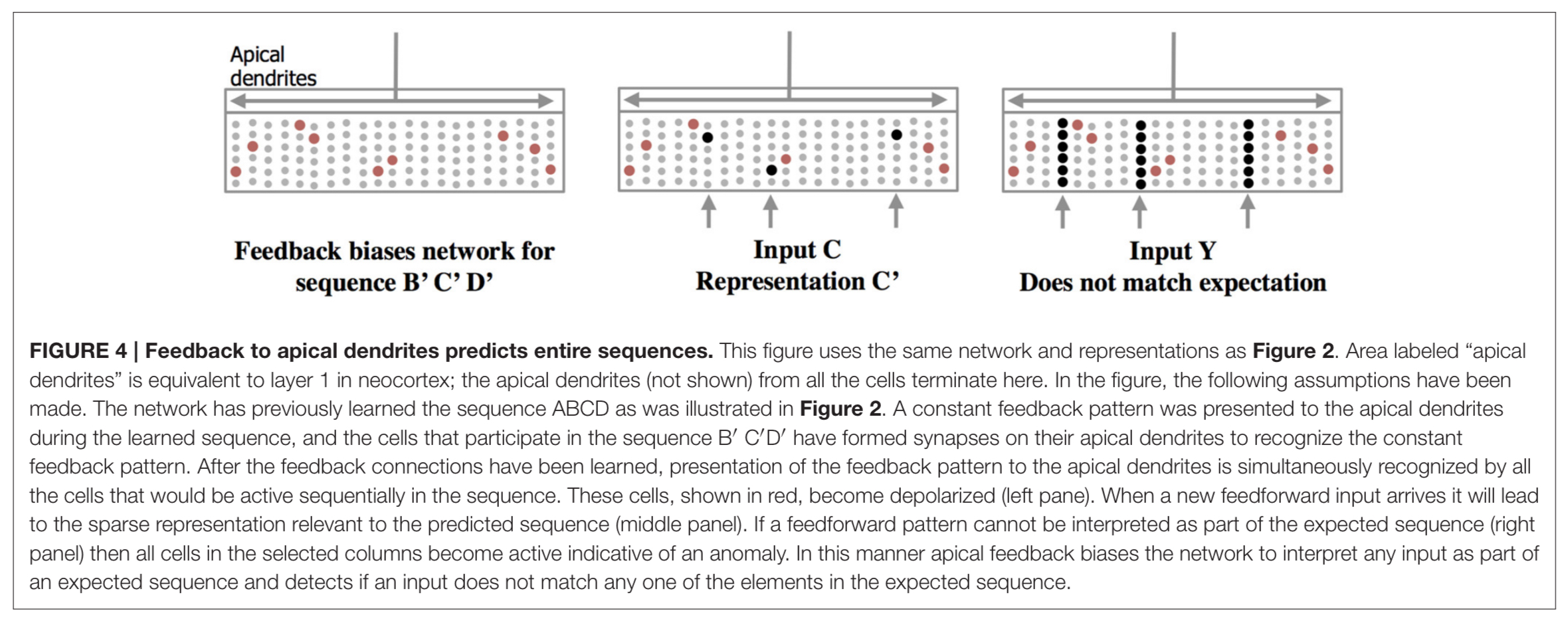
(Enlarge)
{kind=link}
The HTM model neuron
The authors model the biology of the brain in software with Hierarchical Temporal Memory (HTM) neurons.
We model a cell’s dendrites as a set of threshold coincidence detectors; each with its own synapses. If the number of active synapses on a dendrite/coincidence detector exceeds a threshold the cell detects a pattern. The coincidence detectors are in three groups corresponding to the proximal, basal, and apical dendrites of a pyramidal cell.
Networks built out of HTM neurons use continuous on-line learning with learning rules that are local to each neuron and no global objective function. For each dendritic segment a set of ‘potential’ synapses between the segment and other cells in the network is maintained. A scalar value called ‘permanence’ models the growth of the synapse. Permanence values close to zero indicate that although potential to grow a synapse exists, one has not started growing yet. Values close to one represent a large fully-formed synapse.
The permanence value is incremented and decremented using a Hebbian-like rule. If the permanence value exceeds a threshold, such as 0.3, then the weight of the synapse is 1, if the permanence value is at or below the threshold, then the weight of the synapse is 0… Using a scalar permanence value enables on-line learning in the presence of noise.
The figure below shows a network being fed a mixture of random elements and repeated sequences. The maximum possible average prediction accuracy based on the input data set is 50%, and this is only possible using higher-order representations. In (A) below the sequences in the data stream were changed after 3000 elements, and the network relearns the new sequences. In (B) varying proportions of the neurons are disabled after the network reaches a stable state, and the performance of the network can be seen to recover as it relearns using the remaining neurons.
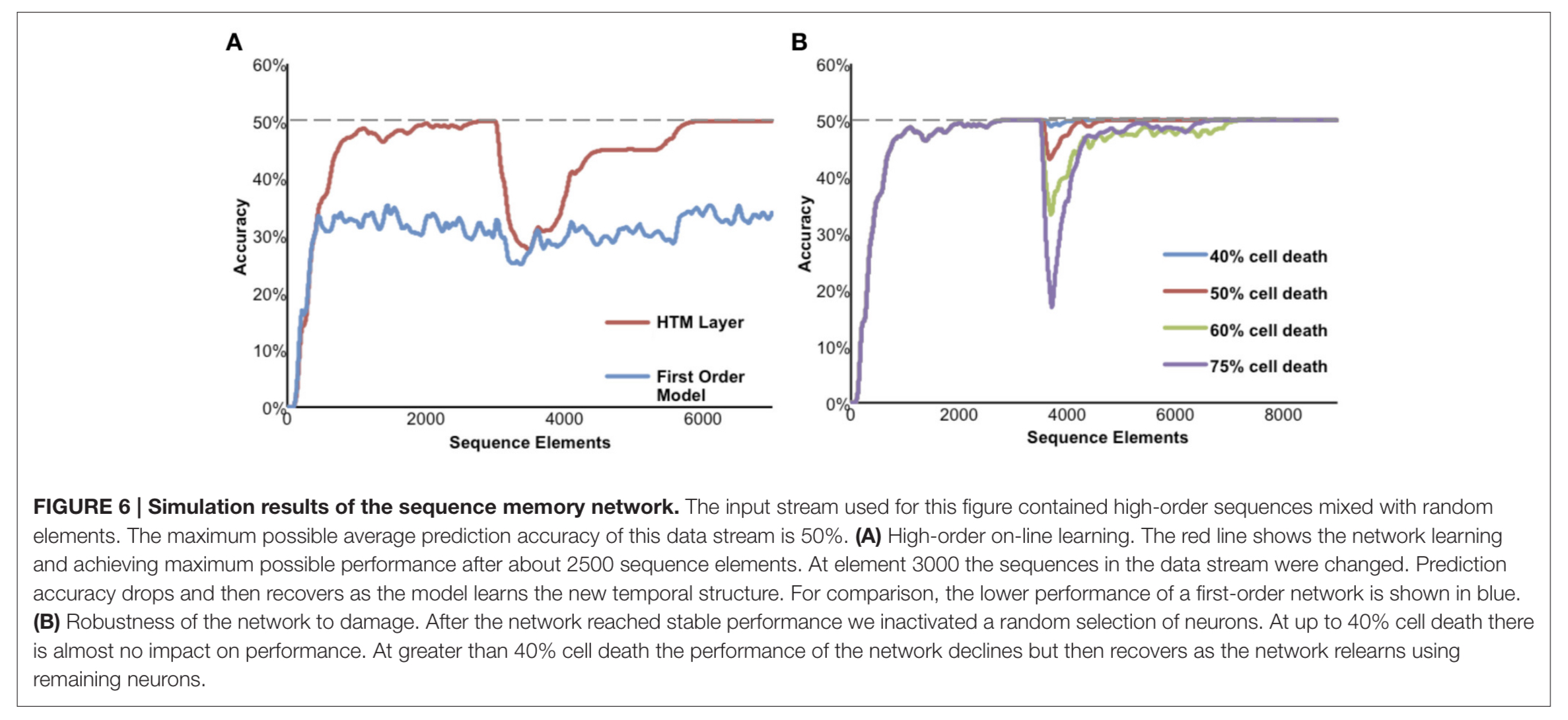
(Enlarge)
{kind=link}
We’ll look at HTM networks in more detail tomorrow.