Data provenance at Internet scale: Architecture, experiences, and the road ahead Chen et al., CIDR 2017
Provenance within the context of a single database has been reasonably well studied. In this paper though, Chen et al., explore what happens when you try to trace provenance in a distributed setting and at larger scale. The context for their work is provenance in computer networks, but many of the lessons apply more broadly to distributed systems in general.
What is provenance? Chen et al. provide a good definition we can work with:
Provenance is, in essence, a way to answer “why” questions about computations. It works by linking each effect, such as a computed value, to its direct causes, such as the corresponding inputs and the operation that was performed on them. Thus, it becomes possible to recursively “explain” a particular result by showing its direct causes, and then their own causes, and so on, until a set of basic inputs is reached. This explanation is the provenance of the result: it is a tree whose vertexes represent computations or data and whose edges indicate direct causal connections.
Note carefully that tracing provenance means being able to trace both the original inputs, and the operations (i.e., code in some form or other) that processes them. So we’re back to the kind of giant distributed graphs with versioning information for both code and data that we saw yesterday with Ground.
Here’s an interesting juxtaposition: this is a 2017 research paper looking at what might be necessary to explain computation results in a distributed setting. The GDPR (sorry to keep going on about it!), which becomes law in the EU in May 2018 makes it a legal requirement to be able to do so when the inputs relate to people and the computed value to be explained is some decision that affects them.
Some of the key challenges and opportunities in extending provenance to a distributed setting that the authors explore include:
- partitioning provenance information across nodes
- adding temporal information so that questions can be asked about past states
- protecting provenance information against attacks (which it can otherwise be used to help diagnose and defend against)
- extending provenance to cover not only data but also code
- using provenance to ask ‘why not?’ questions (something expected did not happen)
- using provenance differences between correct and faulty output to help establish cause
The basic architecture of the ExSPAN system is as follows:
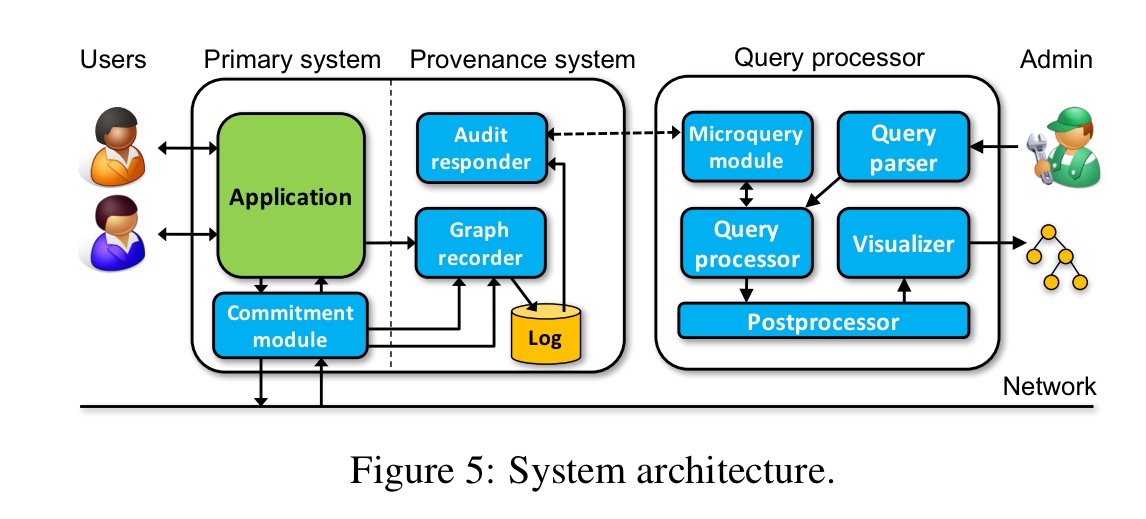
The graph recorder captures provenance from an application running on a given node and records it in a local log. The (optional) commitment module adds cryptographic commitments to outgoing messages, and verifies incoming messages. The audit responder sends excerpts from the log to the query processor when they are needed to respond to a query. Note that this architecture seems to rely on a fairly static set of nodes, and on reliable persistent of their local logs – just as with regular exhaust logs we could imagine replacing this with a more sophisticated distributed storage mechanism that survives independent of any one node.
The graph recorder itself has three options for extracting provenance information: in the lucky case, the application is written in a declarative language (e.g., NDlog) that permits extraction of provenance directly through its runtime. With source code availability the application can be instrumented to make calls to the recorder, if only binary is available, ‘provenance can still be extracted through an external specification’. I can think of another couple of options: the application could emit provenance events that the recorder subscribes too, and some provenance could be recovered through exhaust logs as in The Mystery Machine or lprof.
The provenance graph
ExSPAN is built for provenance in computer networks, so at the core it has vertices representing network events and rules, and edges between them to show the flow of packets. This graph is partitioned and distributed across many nodes. ExSPAN uses incremental view maintenance techniques on the provenance information to make queries efficient.
Extending the provenance graph with temporal information to be able to answer historical questions required the graph to move to an append-only model, and the addition of several new vertex types (EXIST, INSERT, DELETE, APPEAR, DISAPPEAR, DERIVE, and UNDERIVE). The meaning and usage of these vertices is fully explained in an earlier paper. At this point, provenance information starts to expand in volume. To keep this in check, one option is to record only inputs and non-deterministic events, deriving everything else upon query. The familiar approach of recording snapshot states (as you might do when reconstructing state from an event log) to speed up this reconstruction can then be used.
We also have a need for secure forensics, since today’s networks and computers are targets of malicious attacks. In an adversarial setting, compromised nodes can tamper with their local data and/or lie to other nodes… therefore when performing forensics, it is important to validate the integrity of the provenance data.
To address this need, SEND, RECEIVE, and BELIEVE vertex types are added to the graph. BELIEVE tuples are added when a node receives a tuple from another node, recording the belief that the tuple was indeed seen on the other node. These are stored in a tamper-evident log so a node can always prove details of its past interactions. The model (again, fully described in an earlier paper) provides two guarantees:
a) if any behavior is observable by at least one correct node, then the provenance of that behavior will be correct, and b) if a correct node detects a misbehavior, it can tell which part of the provenance is affected, and attribute the misbehavior to at least one faulty node. Our prototype shows that this model works well for BGP routing, Chord DHT, and Hadoop MapReduce applications.
To be able to answer why something good failed to happen, the graph can be further extended with negative vertices enabling counterfactual reasoning. The approach reminds me of Molly:
At a high level, negative provenance finds all possible ways in which a missing event could have occurred, and the reason why each of them did not happen . As a result, this enhancement creates a ‘negative twin’ for each vertex type (except for BELIEVE).
Here’s an example of a provenance graph tracing a missing HTTP request:

Differential provenance
By reasoning about the differences between the provenance trees for working and non-working instances, it becomes much easier to identify the root cause of problems. The team call this approach differential provenance.
One challenge in networks is that a small, initial difference can lead to wildly different network executions afterwards – for instance, a different routing decision may send packets down an entirely different path. Therefore, the differences between working and non-working provenance trees can be much larger than one might expect. Differential provenance addresses this with a counterfactual approach: it “rolls back” the network execution to a point where the provenance trees start to diverge; then, it changes the mismatched tuple(s) on the non-working provenance tree to the correct version, and the “rolls forward” the execution until the two trees are aligned.
Meta provenance
Software defined networking means that you can have bugs in software as well as in hardware! Thus you might want to include not just data but also code in your provenance graph. I think of the code as a first class part of provenance just like the data, but in ExSPAN the extension to also reason about program code goes under the name ‘meta provenance.’
Meta provenance has a set of meta tuples, which represent the syntactic elements of the program itself, and a set of meta rules, which describe the operational semantics of the programming language.
I guess the ‘meta’ prefix is here because these are rules that describe how the regular data tuples are generated / manipulated.
The use case for meta provenance that the authors give is automated network repair, where changes to the program and/or configuration data can be automatically explored to find what it takes to make a desired outcome become true. This of course requires your program to be expressed in a suitable language… “we have validated this approach by finding high-quality repairs for moderately complex SDN programs written in NDlog, Trema, and Pyretic.”
Provenance and privacy
Collecting provenance information while preserving privacy is still an open problem!
Using provenance to diagnose network problems that span multiple trust domains remains an open problem. Provenance is easier to collect within a single trust domain, e.g., in a centralized database or an enterprise network; but collecting and analyzing provenance while providing strong privacy guarantees seems to be a challenging problem, e.g., when performing diagnostics in a multi-tenant cloud.
Possible pieces of the puzzle may include differential privacy, secure multi-party computation, and/or trusted hardware platforms.