SnappyData: A unified cluster for streaming, transactions, and interactive analytics Mozafari et al., CIDR 2017
Update: fixed broken paper link, thanks Zteve.
On Monday we looked at Weld which showed how to combine disparate data processing and analytic frameworks using a common underlying IR. Yesterday we looked at Peloton that adapts to mixed OLTP and OLAP workloads on the fly. Today it’s the turn of SnappyData (snappydata.io), which throws one more ingredient into the mix: what if we need OLTP + OLAP + Streaming (which let’s face it, many applications do). I should add a disclaimer today that several of the authors of this paper are friends and ex-colleagues from my days at Pivotal and VMware.
Here’s a motivating example: consider a real-time market surveillance system ingesting trade streams and detecting abusive trading patterns. We need to join the incoming trade streams with historical records, financial reference data, and other streams of information. Triggered alerts may result in further analytical queries. You can build systems like this by aggregating a stream processing engine, online data store, and an OLAP system but there are disadvantages to running multiple systems:
- Significantly increased operational complexity
- Inefficiencies and reduced performance caused by data movement and /or replication across clusters
- It’s very hard to reason about overall consistency across systems when each has its own consistency guarantees and recovery models.
[SnappyData] aims to offer streaming, transaction processing, and interactive analytics in a single cluster, with better performance, fewer resources, and far less complexity than today’s solutions.
It does this by fusing together Apache Spark with Apache Geode (aka GemFire) – a distributed in-memory transactional store.
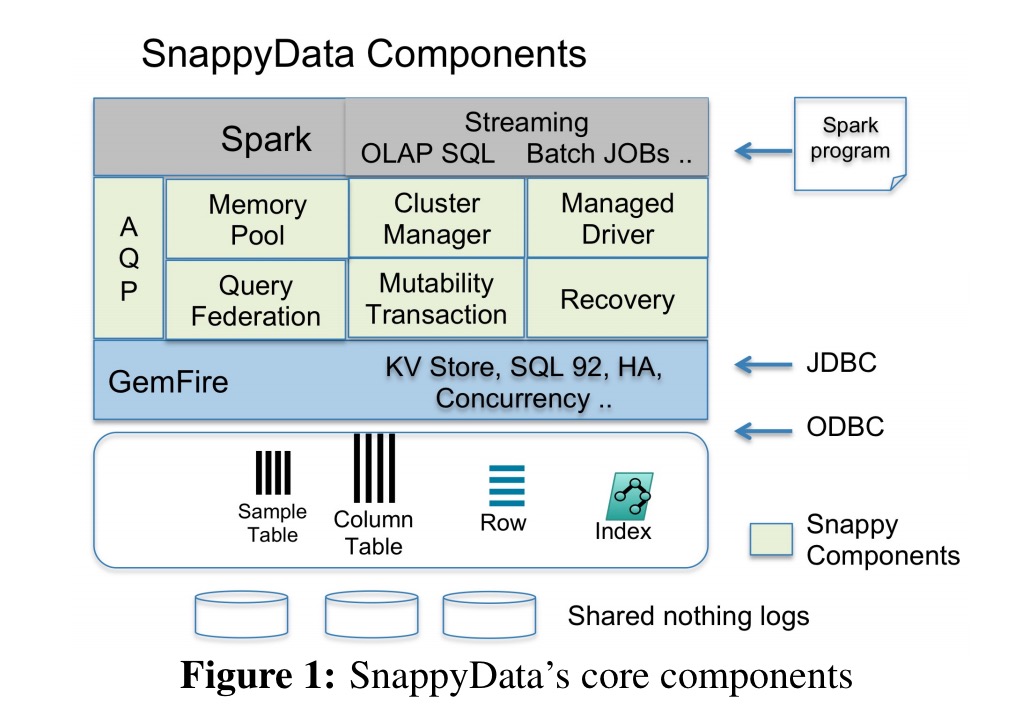
The Snappy Data programming model is a pure extension of the Spark API (also encompassing Spark SQL and Spark Streaming). The hybrid storage layer is primarily in-memory, and can manage data in row, column, or probabilistic stores. The column format is derived from Spark’s RDDs, the row-oriented tables from GemFire’s table structures (bringing support for indexing).
I’m particularly interested to see the probabilistic store for approximate query processing (AQP). My personal sense is that AQP is significantly under-utilised in practice when compared to its potential (we previously looked at e.g., ApproxHadoop, and BlinkDB is well worth learning about too. I think there’s even an old talk by me on probabilistic data structures kicking around on the internet somewhere!).
… SnappyData can also summarize data in probabilistic data structures, such as stratified samples and other forms of synopses. SnappyData’s query engine has built-in support for approximate query processing (AQP) which can exploit the probabilistic structures. This allows applications to trade accuracy for interactive-speed analytics on streams or massive datasets.
The supported probabilistic data structures include uniform samples, stratified samples, and sketches. Uniform sampling simply means that every element has an equal chance of being included in the sample set, with samples being chosen at random. Stratified sampling is the process of dividing a population into homogeneous subgroups (strata) before sampling. Per wikipedia, there are a couple of other considerations that need to be taken into account:
The strata should be mutually exclusive: every element in the population must be assigned to only one stratum. The strata should also be collectively exhaustive: no population element can be excluded
Sketches are wonderful data structures for maintaining approximate counts, membership tests, most frequent items and so on.
From these data structures, SnappyData uses known algorithms for error estimation when processing queries (see ‘The analytical bootstrap…‘ and ‘Knowing when you’re wrong…‘ – we should really look at those papers in more detail in future editions of The Morning Paper). The innovation is in the way that SnappyData builds and maintains the structures in the first place.
Unlike uniform samples, choosing which stratified samples to build is a non-trivial problem. The key question is which sets of columns to build a stratified sample on. Prior work has used skewness, popularity and storage cost as the criteria for choosing column-sets. SnappyData extends these criteria as follows: for any declared or foreign-key join, the join key is included in a stratified sample in at least one of the participating relations (tables or streams).
The WorkloadMiner tool, integrated into CliffGuard can be used to generate statistics to help users choose the right strata.
Tuples arriving in a stream are batched into groups of (by default) 1M tuples and samples for the each of the observed stratified columns are captured in memory. Once the batch is complete it can then be safely stored in a compressed columnar format and archived to disk if desired.
A quick word on tables
Tables follow GemFire’s lead and can be managed either in Java heap memory or off-heap. Tables can be co-partitioned (so that frequently joined tables are partitioned together) or replicated. A core use case for replicated tables is the support for star schemas with large (partitioned) fact tables related to multiple smaller dimension tables. The dimension tables can be replicated to optimise joins.
Behind the scenes, Spark’s column store is extended to support mutability:
Updating row tables is trivial. When records are written to column tables, they first arrive in a delta row buffer that is capable of high write rates and then age into a columnar form. The delta row buffer is merely a partitioned row table that uses the same partitioning strategy as its base column table. This buffer table is backed by a conflating queue that periodically empties itself as a new batch into the column table. Here, conflation means that consecutive updates to the same record result in only the final state getting transferred to the column store.
Performance evaluation
The main intended benefit of SnappyData is not pure performance, but a reduction in the operational complexity from not having to manage multiple disparate systems. However, we do get a comparison of SnappyData’s performance against Spark+Cassandra and Spark+MemSQL baselines. The test workload is based on advertising analytics, and includes streaming, transactional, and analytical components. The streaming component receives a stream of impression events, aggregates them by publisher and geographical region, and computes the average big, number of impressions, and number of uniques every few seconds. The analytical queries execute over the full history and return (1) top 20 ads by number of impressions for each geography, (2) top 20 ads receiving the most bids by geography, and (3) top 20 publishers receiving the most bids overall.
We can see how the systems fared in the results below. The analytical queries were run after ingesting 300M records.
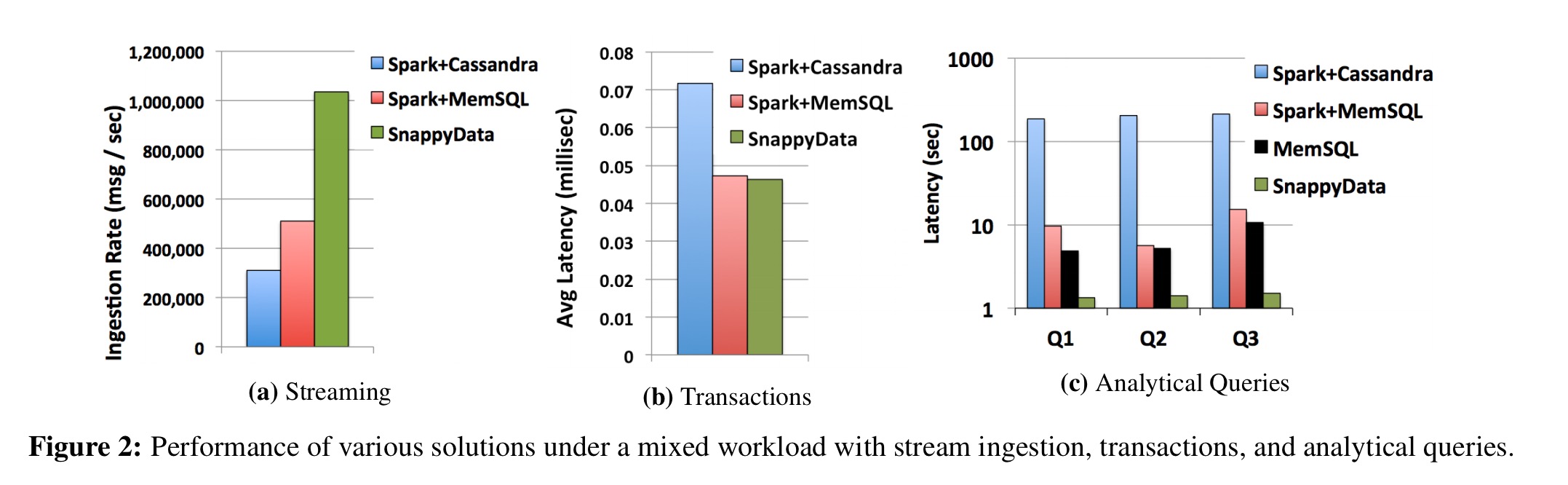
SnappyData ingests data faster than either of the other two systems (the text says up to 2x, but the chart reads like 3x), and also processes transactions marginally faster, but it’s in the analytical queries where it really seems to shine.
Spark+Cassandra pays a heavy price for serializing and copying data to the Spark cluster for processing. The Spark+MemSQL connector does push as much of the query processing as possible down to MemSQL, giving it performance close to that of native MemSQL. Why does SnappyData perform so better than MemSQL on this particular use case then?
SnappyData embeds its column store alongside Spark executors,
providing by-reference data access to rows (instead of by-copy). SnappyData also ensures that each partition at the storage layer
uses its parent’s partitioning method. Thus, each update becomes a local write (i.e., no shuffles). When queried, SnappyData’s data is column-compressed and formatted in the same format as Spark’s, leading to significantly lower latencies.
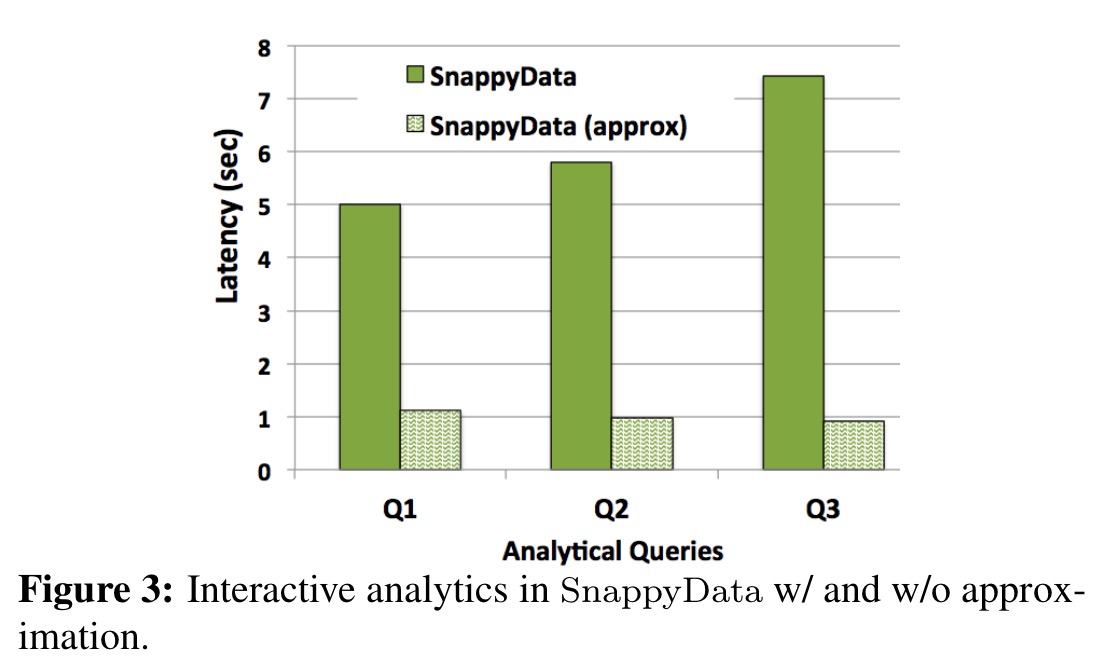
Let’s finish with a reminder of the power of AQP. After ingesting 2 billion ad impressions approximate queries with an error tolerance of 0.05 were up to 7x faster than their exact SnappyData equivalents.