Matching networks for one shot learning Vinyals et al. (Google DeepMind), NIPS 2016
Yesterday we saw a neural network that can learn basic Newtonian physics. On reflection that’s not totally surprising since we know that deep networks are very good at learning functions of the kind that describe our natural world. Alongside an intuitive understanding of physics, the authors of “Building machines that learn and think like people” also called out one-shot learning as a capability which humans have and which machine learning systems struggle with. Today’s paper choice sees the Google DeepMind team take on that challenge:
Learning from a few examples remains a key challenge in machine learning. Despite recent advances in important domains such as vision and language, the standard supervised deep learning paradigm does not offer a satisfactory solution for learning new concepts from little data.
Suppose I say to you “a Rebra is a Zebra but with red and white stripes,” and then show you a sample image. You’d then be able to tell me which other pictures had Rebras in them. The one-shot learning challenge is similar: the system is shown a single labelled example and from this it should be able to learn to detect other examples of the same class.
Deep learning isn’t very good at this – it needs lots of examples to drive lots of iterations of stochastic gradient descent and gradually refine the weights in the model. In contrast, something like k-nearest neighbours (KNN) doesn’t require any training at all. Suppose we see only 1 example of a class as in one-shot learning. If we used 1-NN and thus predicted the class of a previously unseen input as its nearest neighbour we’d have a basic system. Unfortunately it probably wouldn’t work very well in the real world, and we still have the problems of learning a good feature representation and choosing an appropriate distance function.
The Matching Nets architecture described in this paper blends these two extremes, using neural networks augmented with memory (as we saw for example in Memory Networks and the Neural Turing Machine). In these models there is some external memory and an attention mechanism which is used to access the memory. It’s a network that learns how to learn a classifier from only a very small number of examples…
A matching network is shown a support set S of k labelled examples with input x and label y : 

")
")

y_i")
Here 



For the attention mechanism itself, the authors use the cosine distance between
Plugging into the softmax formula:

we get
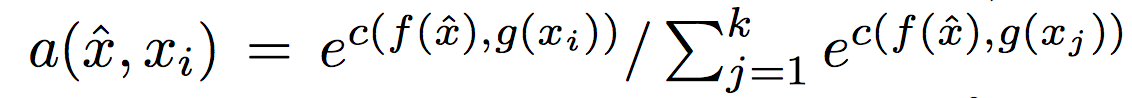
At this point a picture is probably very helpful:
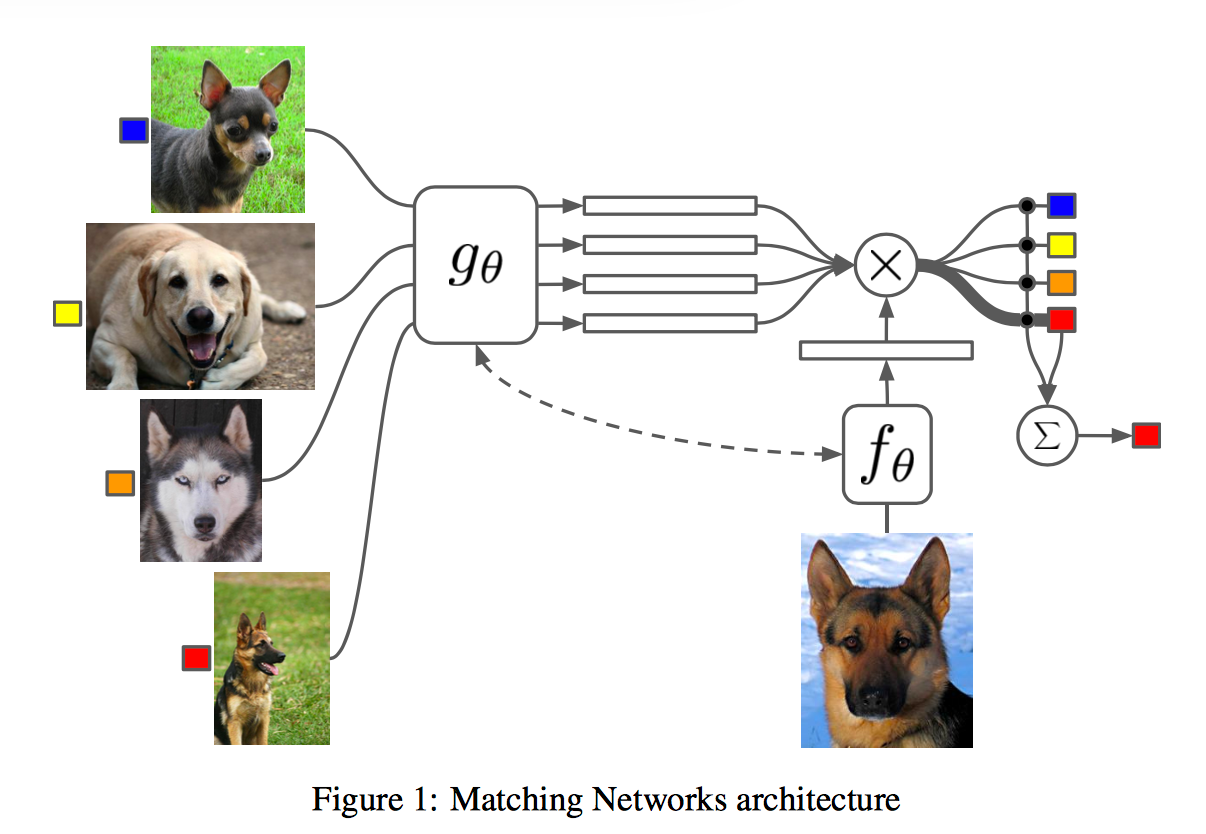
You’re probably wondering why we use different embedding functions for ")


You get good at what you practice
If you want to become good at learning a classifier given only a very small number of examples, then it makes sense to train that way!
To train a matching net, first sample a small number of labels (e.g., the set {cats, dogs}), and then sample a support set S with a small number of examples per label (e.g. 1-5), and a batch B to be used to training.
The Matching Net is then trained to minimise the error predicting the labels in the batch B conditioned on the support set S. This is a form of meta-learning since the training procedure explicitly learns to learn from a given support set to minimise a loss over a batch.
Experiments
Matching Networks were tested on a number of N-way (N labels/classes), k-shot (k examples per class) learning tasks. Data sets were drawn from the Omniglot and ImageNet image data sets, and the Penn Treebank language modelling data set.
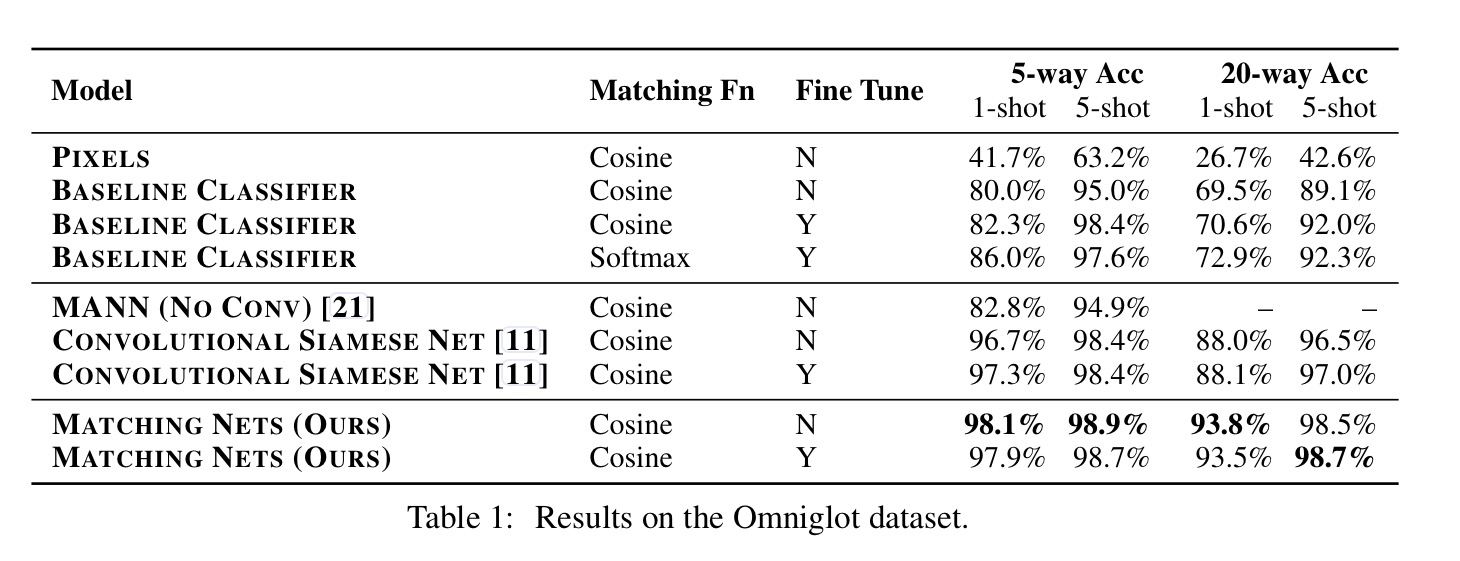
Omniglot contains 1623 characters from 50 different alphabets, each hand-drawn by 20 different people. A CNN was used as the embedding function. In both 1-shot and 5-shot, 5-way and 20-way tests, Matching Networks outperform a baseline of the state-of-the-art MANN classifier, as well as a Convolutional Siamese Net (neither of these were designed for one-shot learning of course).
A variety of experiments were performed with the ImageNet dataset. The miniImageNet test used 60,000 images with 100 classes, each having 600 examples. 80 classes were used for training, and testing was done on the other 20. Here are a couple of examples of Matching Networks classifying in a 5-way test (vs the Inception baseline):

Here are the detailed results:
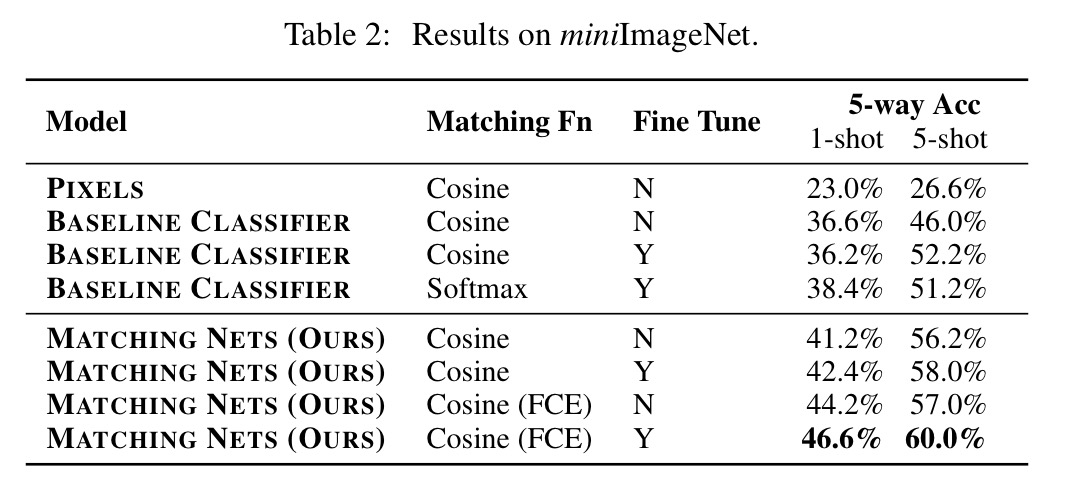
Note the row labelled ‘FCE’, which stands for ‘Full Contextual Embedding’ (i.e., passing S into g and f) – which turns out to be worth about 2 percentage points for one-shot learning on this task.
The language task is to take a query sentence with a missing word, and predict the missing word (class). The support set contains sentences with a missing word and corresponding label for the missing word. An LSTM oracle which sees all the data (i.e., is not one-shot) defined an upper bound for this task of 72.8% accuracy. Matching Networks achieved 32.4%, 36.1%, and 38.2% accuracy with k = 1, 2, 3.
In this paper we introduced Matching Networks, a new neural architecture that, by way of its corresponding training regime, is capable of state-of-the-art performance on a variety of one-shot classification tasks. There are a few key insights in this work. Firstly, one-shot learning is much easier if you train the network to do one-shot learning. Secondly, non-parametric structures in a neural network make it easier for networks to remember and adapt to new training sets in the same tasks.
(Non-parametric here is referring to the use of the memory, as opposed to having to try and encode everything that has been seen solely in trained weights).