Slicer: Auto-sharding for datacenter applications Adya et al. (Google) OSDI 2016
Another piece of Google’s back-end infrastructure is revealed in this paper, ready to spawn some new open source implementations of the same ideas no doubt. Slicer is a general purpose sharding service. I normally think of sharding as something that happens within a (typically data) service, not as a general purpose infrastructure service. What exactly is Slicer then? It has two key components: a data plane that acts as an affinity-aware load balancer, with affinity managed based on application-specified keys; and a control plane that monitors load and instructs applications processes as to which keys they should be serving at any one point in time. In this way, the decisions regarding how to balance keys across application instances can be outsourced to the Slicer service rather than building this logic over and over again for each individual back-end service. Slicer is focused exclusively on the problem of balancing load across a given set of backend tasks, other systems are responsible for adding and removing tasks.
Experience taught us that sharding is hard to get right: the plumbing is tedious, and it can take years to tune and cover corner cases. Rebuilding a sharder for every application wastes engineering effort and often produces brittle results.
Slicer is used by over 20 different services at Google, where it balances 2-7M requests per second from over 100,000 connected application client processes. Slicer has two modes of key assignment, offering both eventually consistent and strongly consistent models. In eventually consistent mode, Slicer may allow overlapping eventually consistent key assignments when adapting to load shifts. In strong consistency mode no task can ever believe a key is assigned to it if Slicer does not agree. All of the production use to date uses the eventually consistent model.
Slicer’s high-level model
Slicer is a general-purpose sharding service that splits an application’s work across a set of tasks that form a job within a datacenter, balancing load across the tasks. A “task” is an application process running on a multitenant host machine alongside tasks from other applications. The unit of sharding in Slicer is a key, chosen by the application.
Application clients use a client-side library called Clerk, and application server tasks integrated with Slicer’s Slicelet library. Slicelet enables a task to learn when a slice is assigned to it, or when a slice is removed from it. The Slicer Service itself monitors load and task availability to generate new key-task assignments and thus manage availability of all keys. It’s up to the application to decide what to use for its keys – they could be fine-grained such as user ids, or coarse-grained as a particular language model to be supported by a speech recogniser.
Slicer hashes each application key into a 63-bit slice key; each slice in an assignment is a range in this hashed keyspace. Manipulating key ranges makes Slicer’s workload independent of whether an application has ten keys or a billion and means that an application can create new keys without Slicer on the critical path. As a result, there is no limit on the number of keys nor must they be enumerated. Hashing keys simplifies the load balancing algorithm because clusters of hot keys in the application’s keyspace are likely uniformly distributed in the hashed keyspace.
Slicer will honour a minimum level of redundancy per-key to protect availability, and automatically increases replication for hot slices.
The Clerk interface provides a single function for finding the addresses of assigned tasks given a key, but in Google most applications don’t use the Clerk library directly and instead benefit from transparent integration with Google’s RPC system Stubby, or Google’s Front End (GFE) http proxy.
The weighted-move sharding algorithm
We balance load because we do not know the future: unexpected surges of traffic arrive at arbitrary tasks. Maintaining the system in a balanced state maximizes the buffer between current load and capacity for each task, buying the system time to observe and react.
Slicer monitors key load (request rate and/or application reported custom metrics) to determine when load balancing changes are required. The overall objective is to minimize load imbalance, the ratio of the maximum task load to the mean task load. When making key assignments Slicer must also consider the minimum and maximum number of tasks per key specified in configuration options, and should attempt to limit key churn – the fraction of keys impacted by reassignment. Key churn itself is a source of additional load and overhead. In order to scale to billions of keys, Slicer represents assignments using key ranges, aka slices. Thus sometimes it is necessary to split a key range to cope with a hot slice, and sometimes existing slices are merged. The sharding algorithm proceeds in five phases:
- Reassign keys away from tasks that are no longer part of the job (e.g., due to hardware failure)
- Increase / decrease key redundancy as required to conform to configured constrained on minimum and maximum number of tasks (the configuration could now be violated due to actions in phase 1, or the configuration itself may have changed)
- Find two adjacent cold slices and merge them into one, so long as the receiving task’s load does not exceed the maximum task load as a result, and the merged slice still has less than mean slice load. Repeat this step so long as: (i) there are more than 50 slices per task in aggregate, and (ii) no more than 1% of the keyspace has moved.
- Pick a sequence of moves with the highest weight (described below) and apply them. Repeat until an empirically determined key churn budget of 9% is exhausted.
- Split hot slices without changing their task assignments. This will open new move options in the next round. Repeat splitting so long as (i) the split slice is at least twice as hot as the mean slice, and (ii) there are fewer than 150 slices per task in aggregate.
During step 4, the weight of a move under consideration is defined as the reduction in load imbalance for the tasks affected by the move, divided by the key churn cost.
The constants in the algorithm (50-150 slices per task, 1% and 9% key movement per adjustment) were chosen by observing existing applications. Experience suggests the system is not very sensitive to these values, but we have not measured sensitivity rigourously.
When balancing based on CPU utilization (one of the available metric options), if the maximum task load is less than 25% then Slicer suppresses rebalancing as no task is at risk of overload.
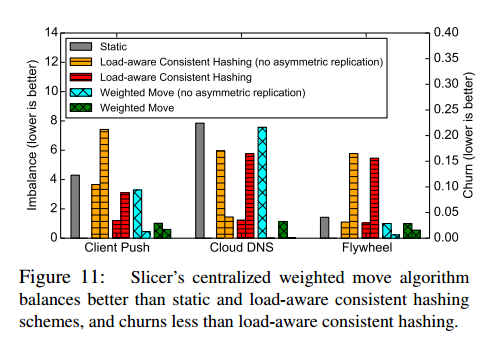
Also of interest to followers of hashing is that the Google team tried consistent hashing schemes and found they didn’t work as well:
A variant of consistent hashing with load balancing support yielded both unsatisfactory load balancing, and large, fragmented assignments.
See §4.4.4 for more details on this.
Slicer’s implementation
Slicer aims to combine the high-quality, strongly consistent sharding decisions of a centralized system with the scalability, low latency, and fault tolerance associated with local decisions.
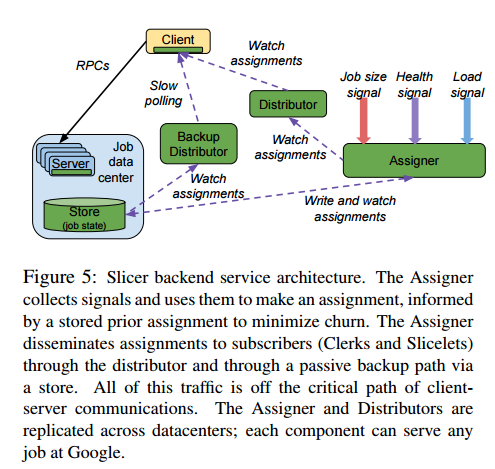
Slicer is conceptually a centralized service, but its implementation is highly distributed. Assigner components run in several Google datacenters around the world and generate assignments using the weighted-move sharding algorithm we just looked at. Decisions are written into optimistically-consistent storage.
A two-tier distributor tree distributes decisions following an assignment change. This happens following a pull-model: subscribers ask a distributor for a job’s assignment, and if a distributor doesn’t have it, it asks the Assigner. Slicer is designed to maintain request routing even in the face of infrastructure failures or failures of Slicer itself. The control-plane / data-plane separation means that most failures hinder timely re-optimization of assignments, but do not delay request routing.
The following part of the fault-tolerating design caught my eye:
The Distributors share a nontrivial code base and thus risk a correlated failure due to a code or configuration error. We have yet to experience such a correlated failure, but our paranoia and institutional wisdom motivated us to guard against it.
To mitigate this, a Backup Distributor service was built on a different code base which is deliberately kept very simple and slowly evolving – it satisifies application requests simply by reading directly from the backing store.
Slicer in production
In a one-week period, Slicer perform 260 billion requests for a subset of its Stubby clients: 99.98% of these succeeded, which establishes a lower bound on Slicer’s availability (requests may have failed for other reasons too). In another week, 272 billion requests arrived for a given backend service, of which only 11.6 million (0.004%) had been misrouted. (Many applications can tolerate misdirected requests with only an impact on latency or overhead, not availability).
There are charts and graphs aplenty in §5 of the paper if that’s your thing!