Firmament: Fast, centralized cluster scheduling at scale Gog et al. OSDI’ 16
Updated link to point to official usenix hosted version
As this paper demonstrates very well, cluster scheduling is a tricky thing to get right at scale. It sounds so simple on the surface: “here are some new jobs/tasks – where should I run them?” Of course the slightly more nuanced question, and where the troubles begin, is “where should I run them in order to optimize for this objective, given these constraints…?” Typically you have a trade-off between distributed schedulers that can operate at scale and make fast decisions, and a centralized scheduler that can make higher quality decisions (e.g, improve utilisation, load balance, or whatever else your policy dictates) but struggles to make those decisions quickly enough as workload scales. What we have here is Firmament, a new centralised scheduler that combines high-quality placements on a par with advanced centralized schedulers, and the speed and scale of a distributed scheduler. It comes from a strong team of researchers across Cambridge, MIT, and Google, and is available in open source at http://firmament.io. A Firmament scheduler plugin for Kubernetes is also under development.
Taking a production workload trace from a 12,500 machine Google cluster, and replaying it at 300x speed, Firmament is able to keep pace and place 75% of tasks with sub-second latency. In a 40-machine test cluster the team compared Firmament against the schedulers from Sparrow, Mesos, Kubernetes, and Docker SwarmKit. At this scale Firmament’s task placement latency is around 5ms. As you can see below, Firmament comes closest to the idle baseline (each task in isolation) above the 80th percentile for a workload consisting entirely of short batch analytics tasks.
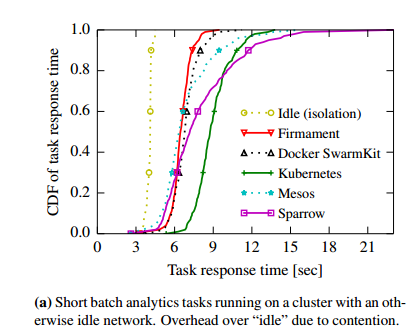
When using a more realistic mix of short tasks with long running interactive services and batch jobs, we see that Firmament greatly improves the tail of the task response time distribution for the short tasks:
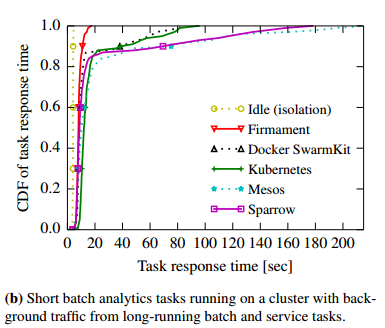
… Firmament’s 99th percentile response time is 3.4x better than the SwarmKit and Kubernetes ones, and 6.2x better than Sparrow’s. The tail matters, since the last task’s response time often determines a batch job’s overall response time (the ‘straggler’ problem).
What do we want from a scheduler?
- Good quality task placements
- Sub-second task placement latency even at scale
- The ability to cope with tricky situations such as a flood of incoming jobs or cluster oversubscription.
Better task placements by the cluster scheduler lead to higher machine utilization, shorter batch job runtime, improved load balancing, more predictable application performance, and increased fault tolerance.
Achieving all of these goals at once of course is hard: task placement requires solving an algorithmically complex optimization problem in multiple dimensions. Low placement latency requires that you make decisions quickly.
Go with the flow
The bird’s-eye view of Firmament looks like this:
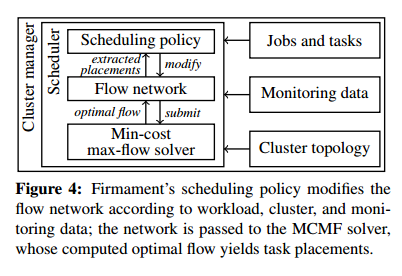
Information about the cluster topology, current system health (monitoring data) and the jobs and tasks to be placed is fed into the Firmament scheduler. Something called a flow network (we’ll get into that shortly) is constructed based on these inputs and the scheduling policy. The flow network is passed to a min-cost, max-flow solver which in turn ouputs the optimal flow. Workload placements are then extracted from this flow graph.
One key feature at this level that helps Firmament produce high-quality decisions is that it addresses task placement by considering the whole workload (new and existing) in one batch as opposed to the more common approach of pulling placement tasks off of a queue one at a time:
… processing one task at at time has two crucial downsides: first, the scheduler commits to a placement early and restricts its choices for further awaiting tasks, and second, there is limited opportunity to amortize work.
The core idea of flow-based scheduling comes from Quincy, and guarantees optimal task placements for a given policy. But Quincy itself is too slow to meet the placement latency targets at scale. In flow-based scheduling, you map the task placement problem into a flow network, use standard min-cost, max-flow optimizations on the network, and then map the results back to task placements. It’s hard to understand without an example, so let’s take a look at a simplified one:
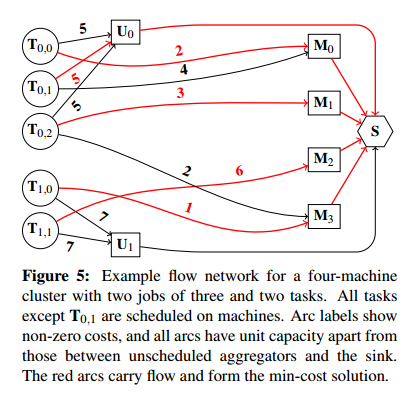
On the left you see the tasks to be placed. They come from two jobs, one with three tasks and one with two tasks. These tasks are the sources of ‘flow’ in the network. On the right hand side you see the single sink node. Everything must flow from the sources (tasks) to the sink through the network in order for placement to be successful. To get to the sink, flow must pass through one of the machine nodes (which implies placement of the task on that machine when the flow graph is mapped backed into the problem domain). Alternatively, a task may remain unscheduled in this particular round, represented by it flowing through an unscheduled node (one per job). The placement preferences are represented as costs on the arcs.
The solver finds the best solution if every task has an arc to each machine scored according to the scheduling policy, but this requires thousands of arcs per task on a large cluster. Policy-defined aggregator nodes, similar to the unscheduled aggregators, reduce the number of arcs required to express a scheduling policy.
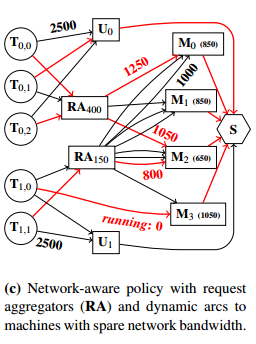
Here’s an example of a mapping for a network aware policy with intermediate request aggregator nodes with arcs representing available bandwidth.
There are a variety of min-cost max-flow (MCMF) algorithms including cycle canceling, succesive shortest path, cost scaling, and relaxation. Successive shortest path for example repeatedly selects a source node and then sends flow from it to the sink along the shortest path. The worst-case complexities of these algorithms are as follows:

So in theory, successive shortest path should work best for this problem.
Theory, meet practice
…since MCMF algorithms are known to have variable runtimes depending on the input graph, we decided to directly measure performance.
That exercise resulted in the following “Big-Oh” moment:
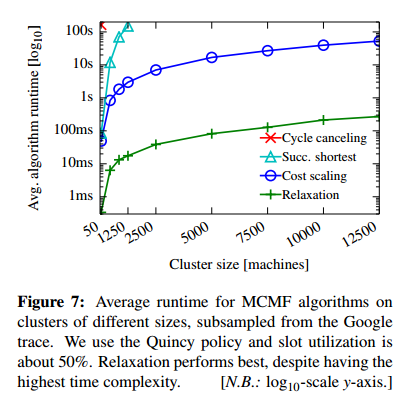
The relaxation algorithm, which has the highest worst-case time complexity, actually performs the best in practice. It outperforms cost scaling (used in Quincy) by two orders of magnitude: on average, relaxation completes in under 200ms even on a cluster of 12,500 machines.
Sometimes there’s a big difference between worst case and expected case! The relaxation algorithm turns out to be particularly efficient when most scheduling choices are straightforward. It’s not always the best choice though. Look what happens when we drive up utilisation:
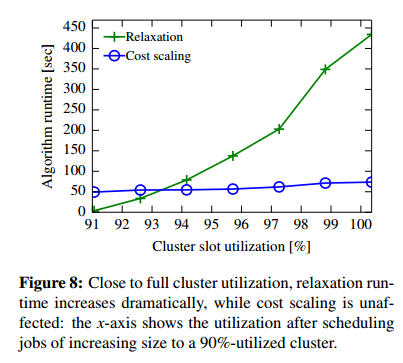
Further investigation (I’m omitting a ton of detail here!) showed that an incremental cost scaling algorithm could improve on the base cost scaling approach by up to 50%, and an arc-prioritisation heuristic reduced relaxation costs by 45%.
In the final implementation, instead of implementing some fancy predictive algorithm to decide when to use cost scaling and when to use relaxation, the Firmament implementation makes the pragmatic choice of running both of them (which is cheap) and uses the solution from whichever one finishes first!
A technique called price refine (originally developed for use within cost scaling) helps when the next run of the incremental cost scaling algorithm must execute based on the state from a previous relaxation algorithm run. It speeds up incremental cost scaling by up to 4x in 90% of cases in this situation.
There is plenty more detail in the paper itself.
The Last Word
Firmament demonstrates that centralized cluster schedulers can scale to large clusters at low placement latencies. It chooses the same high-quality placements as an advanced centralized scheduler, at the speed and scale typically associated with distributed schedulers.