Let’s talk about storage and recovery methods for non-volatile memory database systems Arulraj et al., SIGMOD 2015
Update: fixed a bunch of broken links.
I can’t believe I only just found out about this paper! It’s exactly what I’ve been looking for in terms of an analysis of the impacts of NVM on data storage systems, and the potential benefits of adapting storage algorithms to better exploit the technology. See my “All change please” post from earlier this year for a summary of NVM itself. Today’s paper also contains some background on that, but I’m going to focus on the heart of the material – in which the authors implement three of the common DBMS storage engine strategies and run them on an NVM system to see how they fare, before seeing what improvements can be made when the algorithms are then adapted to be optimised for NVM.
Is NVM going to make a big difference, and will we need to rearchitect to get the most out of it? Yes (although it’s not quite an order-of-magnitude difference):
We then present NVM-aware variants of these architectures that leverage the persistence and byte-addressability properties of NVM in their storage and recovery methods. Our experimental evaluation on an NVM hardware emulator shows that these engines achieve up to 5.5x higher throughput than their traditional counterparts while reducing the amount of wear due to write operations by up to 2x.
A very short primer on NVM
NVM provides low latency reads and writes on the same order of magnitude as DRAM, coupled with persistent writes and a storage capacity similar to SSDs.
NVM can scale beyond DRAM, and uses less power (DRAM consumes about 40% of the overall power consumed by a server). Flash-based SSDs use less power but are slower and only support block-based access.
Although the advantages of NVM are obvious, making full use of them in an OLTP DBMS is non-trivial…
Traditional DBMS engines are designed to cope with orders-of-magnitude differences in latency between volatile and non-volatile storage, and to optimise for block-level granularity with non-volatile storage. Many of the coping strategies employed are unnecessary in an NVM-only system.
The authors perform their tests using an Intel Labs hardware emulator which is able to simulate varying hardware profiles expected from different NVM devices.
The DBMS testbed
The authors study systems that are NVM-only (not two-level or greater storage hierarchies). They developed a single lightweight DBMS testbed into which multiple storage engines can be plugged. Using this consistent harness for all tests means that differences in performance will be due solely to the storage engines themselves. They develop traditional implementations of three storage engines, each using different approaches for supporting durable updates: (i) an in-place updates engine, (ii) a copy-on-write updates engine, and (iii) a log-structured updates engine. After taking a performance baseline for these engines using both YCSB and TPC-C workloads, they then develop NVM-aware derivatives of each of the engines and evaluate those for comparison. We get to see what changes are made, and the difference that they make.
In-Place updates engine
The in-place updates engine keeps only a single version of each tuple at at all times. New values are written directly on top of old ones. The design of the in-place engine used in the study was based on VoltDB. A Write-Ahead Log (WAL) is used to assist in recovery from crashes and power failures, using a variant of ARIES adapted for main-memory DBMSs with byte-addressable storage engines. (See also MARS).
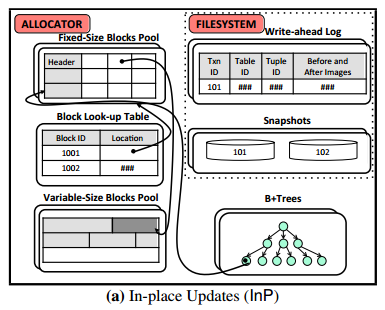
The standard in-place update engine has a high rate of data duplication – recording updates both in the WAL and in the table storage area. The logging infrastructure is designed on the assumption that the durable storage is much slower than memory, and thus batches updates (which increases response latency).
Given this, we designed the NVM-InP engine to avoid these issues. Now when a transaction inserts a tuple, rather than copying the tuple to the WAL, the NVM-InP engine only records a non-volatile pointer to the tuple in the WAL. This is sufficient because both the pointer and the tuple referred to by the pointer are stored on NVM. Thus, the engine can use the pointer to access the tuple after the system restarts without needing to re-apply changes in the WAL. It also stores indexes as non-volatile B+trees that can be accessed immediately when the system restarts without rebuilding.
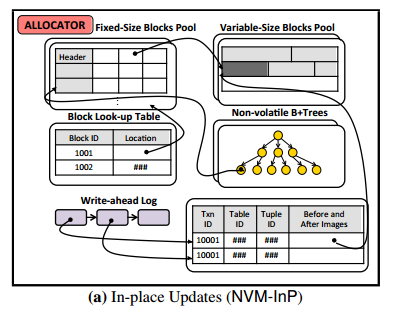
There is no need to replay the log during recovery as committed transactions are durable immediately a transaction commits. The effects of uncommitted transactions that may be present in the database do need to be undone though.
Copy-on-write updates engine
Instead of modifying the original tuple, a CoW engine creates a copy and then modifies that. It uses different look-up directories for accessing versions of tuples (aka shadow paging). There is no need for a WAL for recovery under this scheme. When a transaction commits, the engine updates the master record atomically to point to the new version of a tuple. In the study, the CoW engine uses LMDB’s copy-on-write B-trees, storing directories on the filesystem with tuples in an HDD/SDD optimized format with all fields inlined.
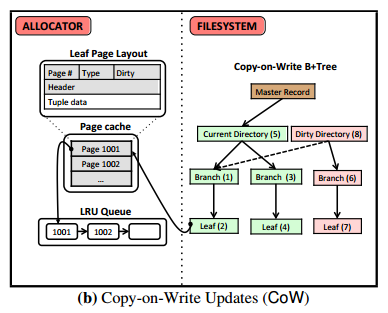
The CoW engine incurs a high overhead in propagating changes to the dirty directory – even if a transaction only modifies one tuple a whole block is copied to the filesystem.
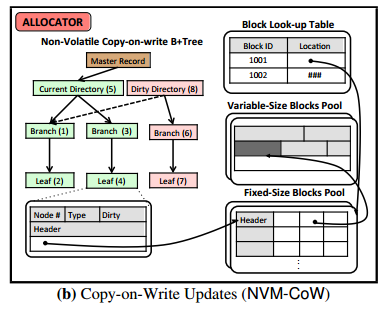
The NVM-CoW engine employs three optimizations to reduce these overheads. First, it uses a non-volatile copy-on-write B+tree that it maintains using the allocator interface. Second, the NVM-CoW engine directly persists the tuple copies and only records non-volatile tuple pointers in the dirty directory. Lastly, it uses the lightweight durability mechanism of the allocator interface to persist changes in the copy-on-write B+tree.
It thus avoids the transformation and copying costs incurred by the original engine.
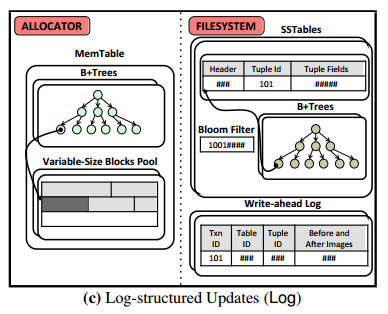
Log-structured updates engine
The log-structured engine employs Log-structured merge (LSM) trees. Each tree consists of a collection of runs of data, each run is an ordered set of entries recording changes made to tuples. Runs reside either in volatile memory or stable storage with changes batched in memory and periodically cascaded out to stable storage. The contents of the memory table are lost on restart, so the engine maintains a WAL.
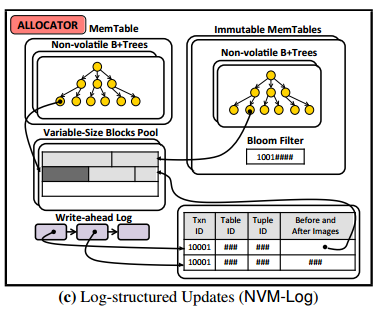
The NVM version using a WAL stored on NVM. It avoids data duplication in the memory table and WAL by recording only non-volatile pointers to tuple modifications in the WAL. Instead of periodically flushing memory tables to stable storage tables (in stable storage optimised format), memory tables are simply marked as immutable .
A few performance comparisons
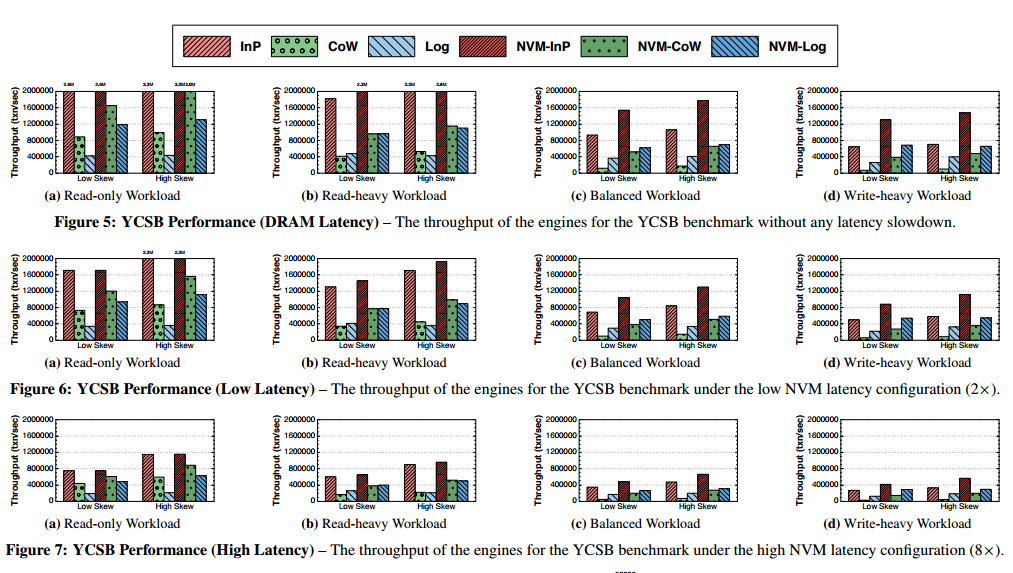
Throughput comparisons at different latencies across the six engines for YCSB:
(Click for larger view)
On YCSB read-only workloads, NVM-InP is no faster than In-P, but NVM-CoW is 1.9-2.1x faster than straight CoW, and NVM-Log is 2.8x faster than Log. Under balanced and write-heavy workloads the NVM variants do much better, the NVM-CoW engine being 4.3-5.5x faster than straight CoW. Under TPC-C the NVM engines are 1.8-2.1x faster than the traditional engines.
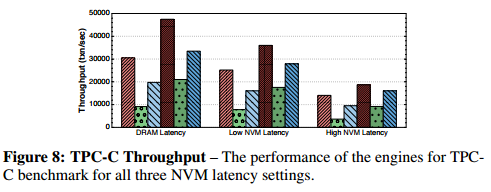
And for TPC-C:
Example of the difference in number of reads and writes (TPC-C):
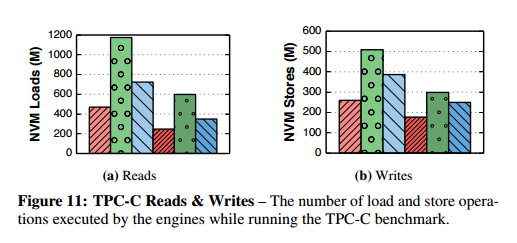
On YCSB the NVM-aware engines perform up to 53% fewer loads, and 17-48% fewer stores on write-heavy workloads. For TPC-C, the NVM-aware engines perform 31-42% fewer writes.
Total storage footprints:
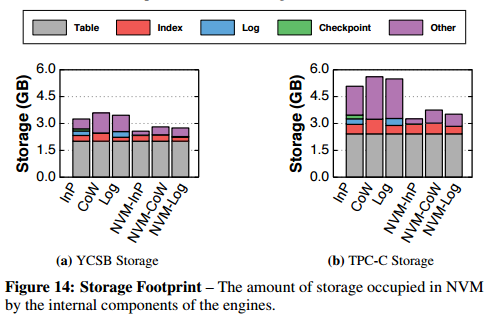
NVM-InP and NVM-Log use 17-21% less storage on YCSB, and NVM-CoW uses 25% less. The NVM engines use 31-38% less storage on TPC-C – the space savings are more significant due to the write-intensive workload with long-running transactions.
The takeaway
NVM access latency is the most significant factor in determining the runtime performance of the engines. The NVM aware variants achieve better absolute throughput (up to 5.5x), and perform fewer store operations (less than half for write-intensive workloads) which helps to extend device lifetime. They also use less storage (17-38% depending on workload) overall, which is important because early NVM products are expected to be relatively expensive.
Overall, we find that the NVM-aware In-place engine performs the best across a wide set of workload mixtures and skew settings for all NVM latency configurations…. It achieved the best throughput among all the engines with the least amount of wear on the NVM device.