Consensus on Transaction Commit – Gray & Lamport 2004/5
Last year on The Morning Paper we spent a considerable amount of time looking at consensus protocols. Over the last couple of days we’ve been looking at the two-phase commit protocol. But isn’t two-phase commit just a special purpose version of the consensus problem, where we must reach agreement on one of two values: commit or abort? In today’s paper choice, Jim Gray and Leslie Lamport collaborated to show that this is indeed the case. This has practical consequences: the classic two-phase commit algorithm is blocking and cannot tolerate failures, but consensus algorithms are non-blocking and can tolerate F failures among 2F+1 instances. Gray and Lamport introduce a new commit algorithm, called Paxos Commit that implements two-phase commit (2PC) using Paxos. We get TLA+ specifications both for the traditional 2PC algorithm, and also for Paxos Commit, and the TLA tools are used to prove that Paxos Commit refines 2PC.
Matthew Sackman first brought this paper to my attention last year, when we were discussing his work on Goshawk DB. Goshawk DB takes its safety and liveness guarantees seriously, and uses Paxos Commit for transactions.
The classic transaction commit protocol is Two-Phase Commit, described in Section 3. It uses a single coordinator to reach agreement. The failure of that coordinator can cause the protocol to block, with no process knowing the outcome, until the coordinator is repaired. In Section 4, we use the Paxos consensus algorithm to obtain a transaction commit protocol that uses multiple coordinators; it makes progress if a majority of the coordinators are working.
With 2F+1 coordinators and N Resource Managers, Paxos Commit requires about 2FN more messages than Two-Phase Commit in the normal case. Both algorithms incur the same delay for writing to stable storage (forced log writes). If sending messages is cheaper than writing to stable storage, the cost of a non-blocking protocol should outweigh the additional costs of Paxos Commit.
An abstract model of transaction commit
The paper starts with a very clear and simple description of the requirements for transaction commit:
In a distributed system, a transaction is performed by a collection of processes called resource managers (RMs), each executing on a different node. The transaction ends when one of the resource managers issues a request either to commit or to abort the transaction. For the transaction to be committed, each participating RM must be willing to commit it. Otherwise, the transaction must be aborted. Prior to the commit request, any RM may spontaneously decide to abort its part of the transaction. The fundamental requirement is that all RMs must eventually agree on whether the transaction is committed or aborted…
There are two safety requirements specified:
- Stability – once an RM has entered the committed or aborted state, it stays in that state forever.
- Consistency – it is impossible for one RM to be in the committed state and another in the aborted state.
RMs start in the working state, and can transition to the prepared state in any order. RMs may enter the committed state in any order, but not RM may enter the committed state until all RMs are prepared. Finally, any RM in the working state may enter the aborted state.
We also get two liveness properties:
- Non-triviality says that if the entire network remains non-faulty throughout the execution of the protocol then (a) if all RMs reach the prepared state then they all eventually reach the committed state, and (b) if any RM reaches the aborted state then eventually all RMs reach the aborted state.
- Non-blocking: if a sufficiently large network of nodes stays non-faulty for long enough, then eventually every RM executed on those nodes will eventually reach either the committed or aborted state.
What I very much like is that the appendix to the paper contains full TLA+ specifications of the protocol, starting with the specification of the transaction commit requirements. The authors say:
The main body of this paper informally describes transaction commit and our two protocols. The Appendix contains formal TLA+ specifications of their safety properties—that is, specifications omitting assumptions and requirements involving progress or real-time constraints. We expect that only the most committed readers will look at those specifications.
But I very much hope that you do look at them – the specifications add a degree of clarity that is hard to obtain in prose alone, and you’ll miss out on the beauty of the refinement proofs.
Using the specification, the TLA+ tools are able to verify that the invariants will always hold. We have something simple and provable correct as a foundation…
Two-Phase Commit
The next step is to model the two-phase commit protocol. We looked at that earlier this week, so I won’t repeat it here. A variation on what we saw yesterday is that the protocol begins when one of the RMs sends a prepared message to the coordinator (Transaction Manager).
Two-Phase Commit is described in many texts; it is specified formally in Section A.2 of the Appendix, along with a theorem asserting that it implements the specification of transaction commit. This theorem has been checked by the TLC model checker for large enough configurations (numbers of RMs) so it is unlikely to be incorrect.
To repeat that, the TLA+ specification of two-phase commit contains a THEOREM statement, checked by the TLA+ tool chain, that the specification is a faithful implementation of the simpler Transaction Commit model.
THEOREM TPSpec ⇒ TC!TCSpec
We’ll repeat that trick one more time, when we show that the Paxos Commit specification is also a faithful implementation.
Paxos Commit
This is what we came here for!
The distributed computing community has studied the more general problem of consensus, which requires that a collection of processes agree on some value. Many solutions to this problem have been proposed, under various failure assumptions. These algorithms have precise fault models and rigorous proofs of correctness. In the consensus problem, a collection of processes called acceptors cooperate to choose a value. Each acceptor runs on a different node. The basic safety requirement is that only a single value be chosen. To rule out trivial solutions, there is an additional requirement that the chosen value must be one proposed by a client. The liveness requirement asserts that, if a large enough subnetwork of the acceptors’ nodes is nonfaulty for a long enough time, then some value is eventually chosen. It can be shown that, without strict synchrony assumptions, 2F + 1 acceptors are needed to achieve consensus despite the failure of any F of them. The Paxos algorithm is a popular asynchronous consensus algorithm…
(See Paxos Made Simple for a quick refresher on Paxos. The ‘prepare’, ‘accept’ and ‘learn’ phases are here called simply phase 1, 2 and 3).
Paxos Commit uses a separate instance of the Paxos consensus algorithm to obtain agreement on the decision each RM makes of whether to prepare or abort—a decision we represent by the values Prepared and Aborted. So, there is one instance of the consensus algorithm for each RM. The transaction is committed iff each RM’s instance chooses Prepared; otherwise the transaction is aborted.
A set of acceptors and a leader play the role of Transaction Manager / Coordinator. Let there be N resource managers, and to survive F failures we need 2F+1 acceptors. The message flow for commit in the normal failure free-case is shown below. RM1 is the first RM to enter the prepared state, thus initiating the round.
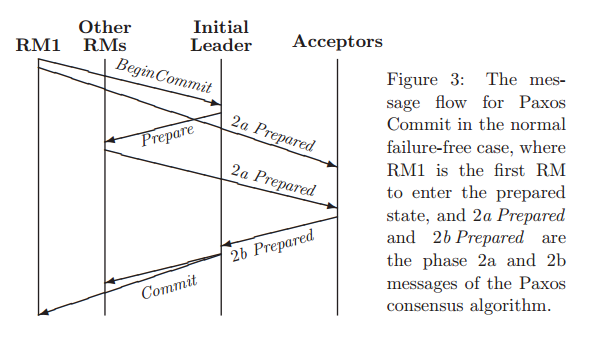
This requires 5 message delays, and the sending of a total of (N+1)(F+3)-2 messages. If we take the reasonable step of assuming the initial leader is on the same node as one of the acceptors, and each acceptor is on the same node as an RM (assuming N ≥ F) , then several of these messages are inter-process on the same machine and can be discounted. Furthermore, phase 3 of Paxos can be eliminated by having each acceptor send its phase 2b messages directly to all the RMs…
We have seen so far the Paxos Commit requires give message delays, which can be reduced to four by eliminating phase 3 and having acceptors send extra phase 2b messages. Two of those message delays result from the sending of Prepare messages to the RMs… these delays can be eliminated by allowing the RMs to prepare spontaneously, leaving just two message delays. This is optimal because implementing transaction commit requires reaching consensus on an RM’s decision, and it can be shown that any fault-tolerant consensus algorithm requires at least two message delays to choose a value… The RMs perform the same writes to stable storage in Paxos Commit as in Two-Phase Commit.
The version of Paxos Commit that is optimised to remove phase 3 of the Paxos consensus algorithm is called ‘Faster Paxos Commit.’ Comparing two-phase commit to the Faster Paxos Commit and assuming co-location of leader and acceptors with RMs we have:
- Four message delays in each case
- 3N – 3 total messages for 2PC, and (N-1)(2F+3) for FPC
- Two stable storage write delays in each case
- N+1 total force-writes for 2PC, and N+F+1 for FPC
Consider now the trivial case of Paxos Commit with F=0, so there is just a single acceptor and a single possible leader, and the algorithm does not tolerate any acceptor faults. (The algorithm can still tolerate RM faults)… Two-Phase Commit and Paxos Commit use the same number of messages, 3N-1 or 3N-3 dependent on whether or not co-location is assumed. In fact, Two-Phase Commit and Paxos Commit are essentially the same when F=0. The two algorithms are isomorphic… The Two-Phase Commit protocol is thus the degenerate case of the Paxos Commit algorithm with a single acceptor.
For the clearest description of the actions of resource managers, the current leader, and acceptors, see the TLA+ spec. in the appendix. Once again the model checking tools are used to show that this is a faithful implementation of the Transaction Commit requirements.
Transaction Participants
The description above assumes a single transaction with a fixed set of participating RMs. But in a real system a transaction is first created and then RMs join it. Only those RMs that have joined the transaction participate in the commit/abort decision.
To accommodate a dynamic set of RMs, we introduce a registrar process that keeps track of what RMs have joined the transaction. The registrar acts much like an additional RM, except that its input to the commit protocol is the set of RMs that have joined, rather than the value Prepared or Aborted. As with an RM, Paxos Commit runs a separate instance of the Paxos consensus algorithm to decide upon the registrar’s input, using the same set of acceptors. The transaction is committed iff the consensus algorithm for the registrar cheeses a set of RMs and the instance of the consensus algorithm for each of those RMs chooses Prepared.
See §6 in the paper for the full details of how this works.