Read-Log-Update: A Lightweight Synchronization Mechanism for Concurrent Programming – Matveev et al. 2015
An important paradigm in concurrent data structure scalability is to support read-only traversals: sequences of reads that execute without any synchronization (and hence require no memory fences and generate no contention). The gain from such unsynchronized traversals is significant because they account for a large fraction of operations in many data structures and applications. The popular read-copy-update (RCU) mechanism of McKenney and Slingwine provides scalability by enabling this paradigm. It allows read-only traversals to proceed concurrently with updates by creating a copy of the data structure being modified. Readers access the unmodified data structure while updaters modify the copy. The key to RCU is that once modifications are complete, they are installed using a single pointer modification in a way that does not interfere with ongoing readers.
RCU has been supported in the Linux kernel since 2002, and the User-space RCU library is available for user-space applications. In this paper Matveev et al. take a big step forward beyond RCU with the introduction of an extension to the base RCU ideas they call Read-Log-Update (RLU). RLU provides better performance and concurrency than RCU (it allows multiple simultaneous writers for example), but I think even more importantly it has a much simpler programming model meaning it can be applied to many more scenarios. For example, the RCU-based doubly-linked list in the Linux kernel only allows threads to traverse the list in the forward direction because of the limitations of RCU, whereas the RLU based alternative can easily support traversal in both directions.
I’m going to focus here on the core RLU algorithm. The paper also contains an extensive evaluation section which is a fascinating read, and has the by-product of reminding me just how big our field is and of the huge body of knowledge built up in data structures and algorithms. I collected a good number of additions to my ‘known unknowns’ list reading through it! For example: “We then apply the more advanced RLU scheme with the deferral mechanism of synchronize calls to the state-of-the-art RCU-based Citrus tree, an enhancement of the Bonsai tree of Clements et al. The Citrus tree uses both RCU and fine-grained locks to deliver the best performing search tree to date…”
Let’s dive into how RLU works:
RLU provides support for multiple object updates in a single operation by combining the quiescence mechanism of RCU with a global clock and per thread object-level logs.
The global clock and per-thread object logs will shortly be explained. Just in case the quiescence mechanism of RCU isn’t front-and-centre in your mind right now, here’s a quick refresher:
When [RCU readers] are not inside a critical section, readers are said to be in a quiescent state. A period of time during which every thread goes through at least one quiescent state is called a grace period. The key principle of RCU is that, if an updater removes an element from an RCU-protected shared data structure and waits for a grace period, there can be no reader still accessing that element. It is therefore safe to dispose of it. Waiting for a grace period can be achieved by calling synchronize rcu().
The global clock is a logical clock (counter). All operations read the global clock value before they start, and use this clock value to determine what version of a shared object they should read. A write thread first makes a copy of object to be updated in its write-log, and then modifies the object in the log. This mechanism hides updates from concurrent reads. To avoid conflicts with concurrent writes, each object is also locked before it is duplicated and modified.
Then, to commit the new object copies, a write operation increments the global clock, which effectively splits operations into two sets: (1) old operations that started before the clock increment, and (2) new operations that start after the clock increment. The first set of operations will read the old object copies while the second set will read the new object copies of this writer. Therefore, in the next step, the writer waits for old operations to finish by executing the RCU-style quiescence loop, while new operations “steal” new object copies of this writer by accessing the per thread write-log of this writer. After the completion of old operations, no other operation may access the old object memory locations, so the writer can safely write back the new objects from the writer-log into the memory, overwriting the old objects. It can then release the locks.
Figure 3 from the paper provides a series of worked examples which is probably the best way to quickly grasp the idea. In each of the diagrams that follow, swim-lanes represent threads (T1, T2, T3) and time progress downwards. The global clock and fine-grained object locks are represented in the ‘memory’ column. Full pseudo-code for the algorithm is given in section 3.5 of the paper.
Concurrent reads, no writers
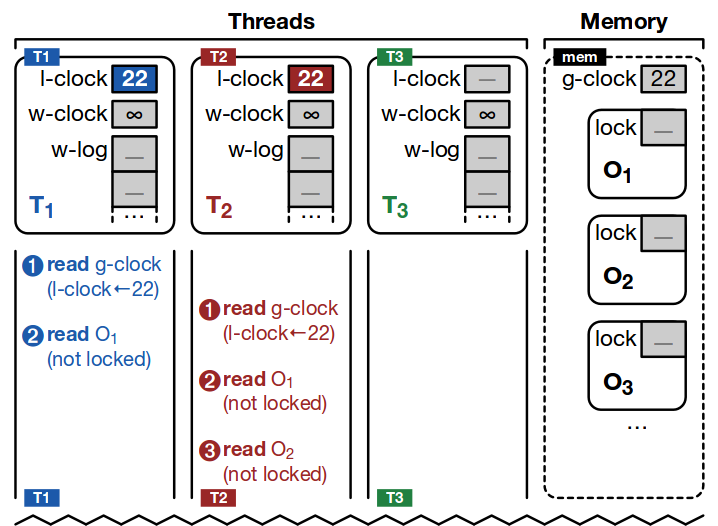
In the example above, threads T1 and T2 both perform reads. They begin by copying the value of the global clock (22) to their local clocks. T1 reads O1, and T2 reads O1 and O2. None of these objects are locked, so reads proceed concurrently from memory.
Concurrent reads with uncommitted writes
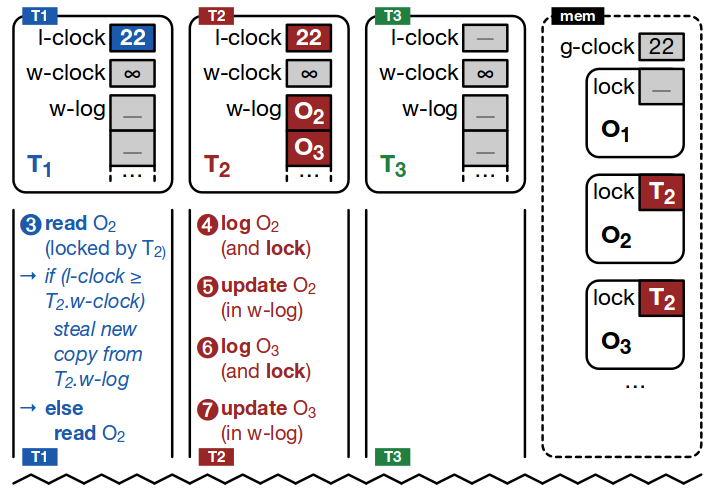
T2 now wants to update objects O2 and O3. Each of these objects is logged (copied into T2’s write-log) and modified in the log. T2 locks these objects using the RLU shared locks (memory column) before logging them.
T1 tries to read O2, after T2 has locked it. T1 sees that T2 holds the lock, and compares its local clock (22) with the value of T2’s write clock (currently at &inf; since T2 has not committed its writes yet). From this comparison we see that this read has not started after a write clock increment (T1’s clock is < T2’s), and so T1 should not try to read O2 from T2’s log (‘steal’ it), but instead should read the object directly from memory.
Committing writes
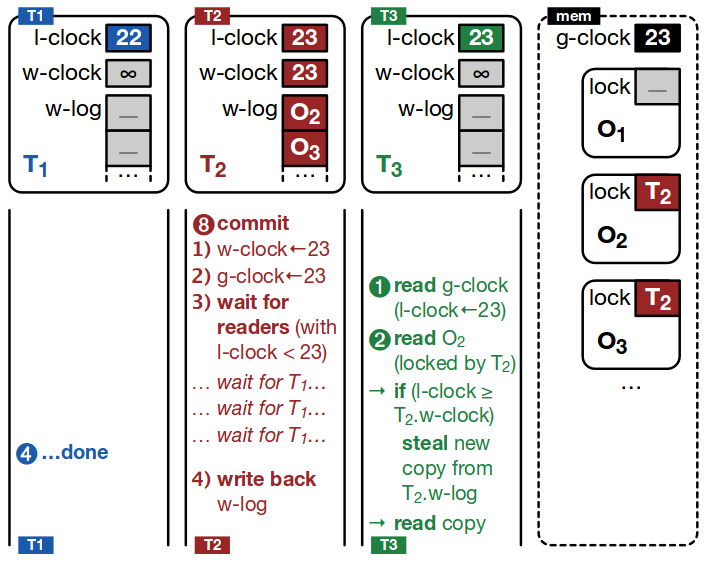
T2 begins the process of committing its writes. It increments the clock value and stores this first in its write-clock, and secondly in the global clock (the order matters). T2 now has to wait for a quiescent point in order to be able to install its updates – it must wait for ‘old’ operations to finish, those with local clock values < its own. In this worked example, that means waiting for T1 to finish. T3 has also started at this point, but has a local clock value of 23 (≥ T2’s), so T2 does not need to wait for it.
When T1 completes, T2 can safely write back the objects in its log to memory and release the locks.
T3 meanwhile wants to read O2 before T2 has been able to install its updates. It compares its local clock value (23) with the write-clock value of T2 (since T2 has the lock at this point), and since its local clock is ≥ T2’s write-clock, it ‘steals’ the value from T2s write-log.
An optimisation – deferring synchronisation
RLU synchronize deferral works as follows. On commit, instead of incrementing the global clock and executing RLU synchronize, the RLU writer simply saves the current write-log and generates a new log for the next writer. In this way, RLU writers execute without blocking on RLU synchronize calls, while aggregating write-logs and locks of objects being modified. The RLU synchronize call is actually only necessary when a writer tries to lock an object that is already locked. Therefore, only in this case, the writer sends a “sync request” to the conflicting thread to force it to release its locks, by making the thread increment the global clock, execute RLU synchronize, write back, and unlock.
This significantly reduces the amount of RLU synchronize calls, as well as contention on the global clock. The aggregration of write-logs and deferring of the global clock update also defers the stealing process to a later time, allowing more reads from memory.