Google’s Hybrid Approach to Research – Spector et al. 2012
Something a little different to close out the week, a paper describing how Google conduct research. It’s a fascinating look at how they balance fundamental and applied research, how they integrate research into product teams, and how they measure the contribution of the research. I especially like the model of embedding research activities within product teams.
Research at Google is built on the premise that connecting research with development provides teams with powerful, production-quality infrastructure and a large user base, resulting not only in innovative research, but also in valuable new commercial capabilities. By coupling research and development, our goal is to minimize or even eliminate the traditional technology transfer process, which has proven challenging at other companies…
With DevOps we’ve taken a major step towards full empowerment of individual teams, and the accountability that goes with that (“you own it, you run it”). As has been forcefully argued by Josh Corman and others, we also need to incorporate security into this model – it needs to be integral in the process to be effective (and we also want the accountability that comes with that – making security ‘somebody else’s’ problem to bolt-on after the fact hasn’t been working very well for us, let’s be honest). So we have DevSecOps. But if we have an empowered team, operating with autonomy, and accountable for its results, why would we stop there? An accountable empowered team should want to continuously improve, and would want to be data-driven – so we need to put some Data Science expertise within the team too: DS-DevSecOps. To the extent that there are research challenges associated with the product/service the team is accountable for, Google make a strong case for integrating that research within the team too: DS-ResDevSecOps. And then we ignore the importance of UX at our peril. Again, if the accountability is with the team, we want to put that in the team: DS-ResDevSecOpsUX. Ok, so the naming’s starting to get a little silly! The overall case I’m trying to make is that once you empower teams and make them accountable, it doesn’t make sense to stop at just Dev and Ops. You own it, you run it, you secure it, you measure it, you design it, you develop it, you improve it, …
Because of the time-frame and effort involved, Google’s approach to research is iterative and usually involves writing production, or near-production, code from day one. Elaborate research prototypes are rarely created, since their development delays the launch of improved end-user services. Typically, a single team iteratively explores fundamental research ideas, develops and maintains the software, and helps operate the resulting Google services – all driven by real-world experience and concrete data. This long-term engagement serves to eliminate most risk to technology transfer from research to engineering. This approach also helps ensure that research efforts produce results that benefit Google’s users, by allowing research ideas and implementations to be honed on empirical data and real-world constraints, and by utilizing even failed efforts to gather valuable data and statistics for further attempts.
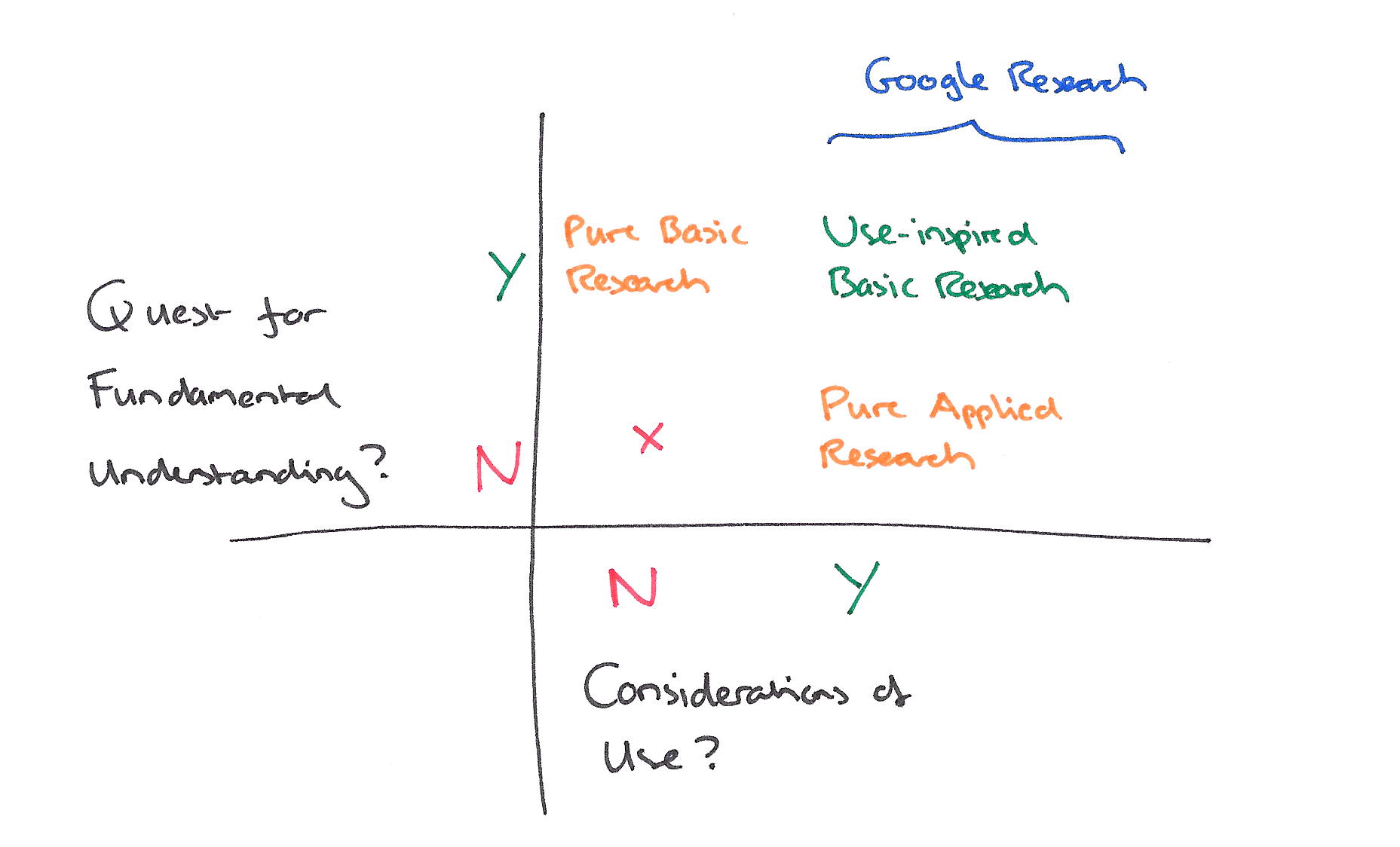
The overall aim of research at Google is to bring significant practical benefits to Google’s users, and to do so within a few years at most. Within Pasteur’s Quadrant model, Google does ‘use-inspired basic’ and ‘pure applied’ CS research.
Google’s “entire organisation is focused on rapid innovation.” This is facilitated by a services-based delivery model, and by hiring individuals capable of moving between projects whether they be primarily research or primarily engineering.
The services-based delivery model brings significant benefits to research and development. Even a small team has at its disposal the power of many internal services, allowing the team to quickly create complex and powerful products and services. Design, testing, production and maintenance processes are simplified. Additionally, the services model, particularly one where there is significant consumer engagement, facilitates empirical research.
Putting this together leads to what Google describe as a “Hybrid Research Model:”
In this model, we blur the line between research and engineering activities and encourage teams to pursue the right balance of each, knowing that this balance varies greatly. We also maintain considerable fluidity in terms of moving both people and projects as needs change. As such, even in areas where there is a much higher proportion of research to engineering, the “Research Team” we have established is not as formally separate from engineering activities as those in other organizations, and for example runs large production systems, too. Overall, we undertake research work when we feel its substantially higher risk is warranted by a chance of more significant potential impact.
Which may lead you to wonder how more speculative or longer-term research can be undertaken in this context. The answer is reminiscent of the response you might give to a developer complaining that large development tasks can’t be undertaken when sprints are one-week long:
In no way do we feel that our model precludes long term research: we just try hard to “factorize” it into shorter-term, measurable components. This provides benefits to us in terms of team motivation (based upon evidence of concrete progress in reasonable time periods) and the potential for commercial benefit (in advance of the complete fulfillment of all objectives)… Clearly, this approach benefits from the mainly evolutionary nature of CS research, where great results are usually the composition of many discrete steps. If the discrete steps required large leaps in vastly different directions, we admit that our primarily hill-climbing-based approach might fail. Thus, we have structured the Google environment as one where new ideas can be rapidly verified by small teams through large-scale experiments on real data, rather than just debated.
This seems a perfectly reasonable posture for research in an industrial setting, but I’m glad that we also have academic institutions where ‘large leaps’ can be contemplated.
The Hybrid Research Model comprises 5 main elements:
- The generation of scientific and engineering advances in fields important to Google.
- Factoring longer projects (which may have very challenging goals) into discrete achievable steps.
- Leveraging Google’s cloud computing models and large user base to support in vivo research.
- Allowing for the maximal amount of organizational flexibility to support projects that require room to grow unfettered by current constraints, as well as projects that require close integration with existing products.
- Emphasizing knowledge dissemination using a flexible collection of different approaches.
That last point is a nod to the fact that although Google see value in papers, there are also other ways of disseminating information.
We recognize that the wide dissemination of fundamental results often benefits us by garnering valuable feedback, educating future hires, providing collaborations, and seeding additional work… The way that research results are disseminated is also evolving and the peer-reviewed paper is under threat as the dominant dissemination method. Open source releases, standards specifications, data releases, and novel commercial systems that set new standards upon which others then build, are increasingly important…. In our opinion, a research project is successful if it has academic or commercial impact, or ideally, both. Commercial impact at Google is perhaps easier to measure, and the company has benefitted from numerous advances in systems, speech recognition, language translation, machine learning, market algorithms, computer vision, and more.
The paper briefly describes 5 different research patterns in evidence at Google that illustrate the fluidity between research and development:
- An advanced project in a product-focused team advances the state of the art. MapReduce, GFS, and BigTable were born this way. This is the most prevalent pattern within Google.
- A project starts in the research group and is followed by the operation of a production service based on it. Google Translate and Voice Search followed this pattern.
- A project in the research group creates new concepts or technologies that are then applied to existing products or services. For example, audio and video fingerprinting techniques that were picked up by YouTube engineers.
- A joint project between engineering and research, that is then picked up and used by the engineering team. ” An example for this pattern is the work done by our Market Algorithms group in collaboration with teams working on our advertisement systems. Together, they design, modify and analyze the core algorithms and economic mechanisms used for ad selection and optimization.”
- A research project within an engineering team that is transferred to the research group, and eventually finds its way back into engineering using one of the other patterns described. The work on YouTube recommendations followed this pattern.