Musketeer: all for one, one for all in data processing systems – Gog et al. 2015
Musketeer gives you portability of data processing workflows across across data processing systems. It can even analyse your workflow and recommend the best system to run it on, as well as combining systems for different parts of the workflow. This is important since, as we saw yesterday in part 1, no one system is universally best across all workload sizes and varieties. It works by introducing a DAG-based intermediate representation (IR) and a translator from existing workflow specifications into this IR (all for one). The IR is then analysed and optimised and efficient code is generated for the target back-end system (one for all). You’ll find the paper at the link above, and the open source project at http://www.cl.cam.ac.uk/research/srg/netos/musketeer/.
From front-end to IR
Distributed execution engines simplify data processing by shielding users from the intricacies of writing parallel, fault-tolerant code. However, they still require users to express their computation in terms of low-level primitives, such as map and reduce functions or message-passing vertices. Hence, higher-level “frameworks” that expose more convenient abstractions are commonly built on top. Musketeer supports two types of front-end frameworks: (i) SQL-like query languages, and (ii) vertex-centric graph processing abstractions.
For the SQL-like data analytics front-end code, Musketeer translates the relational operators to operations in the IR DAG; “most relational primitives have directly corresponding Musketeer IR operations.”
(the) vertex-centric programming pattern is generalized by the Gather, Apply and Scatter (GAS) model in PowerGraph. In this paradigm, data are first gathered from neighboring nodes, then vertex state is updated and, finally, the new state is disseminated (scattered) to the neighbors. Musketeer currently supports graph computations via a domain-specific front-end framework built around combining the GAS model with our BEER DSL. Users run graph computations by defining the three GAS steps, with each step represented by relational operators or UDFs. In Listing 2, we show the implementation of PageRank in Musketeer’s GAS front-end framework.
Listing 2:
GATHER = {
SUM (vertex_value)
}
APPLY = {
MUL [vertex_value, 0.85]
SUM [vertex_value, 0.15]
}
SCATTER = {
DIV [vertex_value, vertex_degree]
}
ITERATION_STOP = (iteration < 20)
ITERATION {
SUM [iteration, 1]
}
The set of operators supported by Musketeer is extensible. Mapping a new front-end to Musketeer’s IR takes on the order of a few days, similar to the amount of effort required to add a new back-end.
Optimising the IR
One of the advantages of decoupling front-ends from back-ends is the ability to apply optimizations at the intermediate level, as observed e.g., in the LLVM modular compiler framework. Musketeer can likewise provide benefits to all supported systems (and future ones) by applying optimizations to the intermediate representation.
Musketeer currently performs a small set of standard query rewriting optimizations on the IR. More optimizations happen during the code generation phase.
Generating back-end code
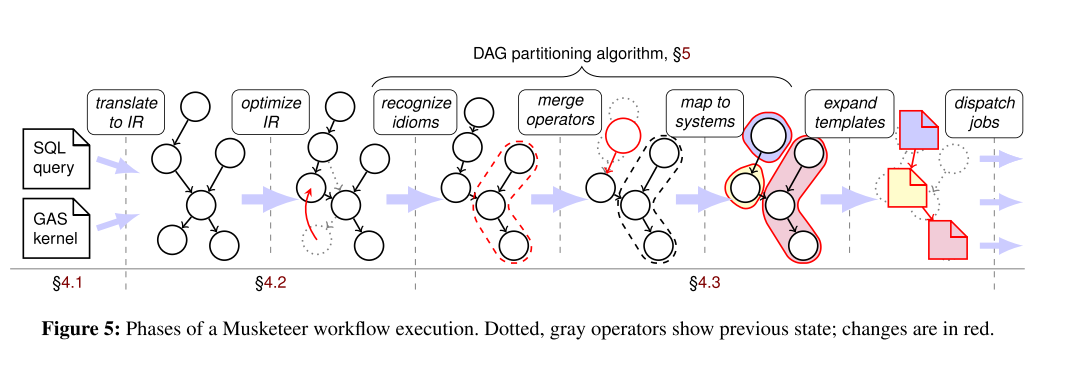
Musketeer has code templates for specific combinations of operators and back-ends. Conceptually, it instantiates and concatenates these templates to produce executable jobs. In practice, however, optimizations are required to make the performance of the generated code competitive with hand-written baselines. Musketeer uses traditional database optimizations (e.g., sharing data scans and operator merging), combined with compiler techniques (e.g., idiom recognition and type inference) to improve upon the naive approach.
Idiom recognition is used to detect graph-processing idioms in the IR, even if they were originally expressed in a relational front-end. Musketeer merges operators to reduce the number of jobs executed. The extent to which this can be done depends on the target system.
To model these limitations and avoid extra jobs when possible, Musketeer has a set of per-back-end mergeability rules. These indicate whether operators can be merged into one job either (i) bidirectionally, (ii) unidirectionally, or (iii) not at all. If execution engines only support certain idioms, only operator merges corresponding to these idioms are feasible. The operator merge rules are used by the DAG partitioning algorithm (§5) to decide upon job boundaries. Operator merging is necessary for good performance: in §6.5, we show that it reduces workflow makespan by 2–5×.
Partitioning a workflow into jobs turns out to be an instance of the NP-Hard k-way graph partitioning problem. Musketeer must solve this for all k A simple extension of the DAG partitioning algorithm allows Musketeer to automatically choose back-end execution engine mappings. To achieve this, we use Musketeer’s cost function and run the DAG partitioning algorithm for all back-ends. We then pick the best k-way partitioning. The cost function scores the performance of a particular combination of operators, input data and execution engine.
Scoring is based on data volume, operator performance (calibrated with one-off per-back-end measurements), and workflow history: metrics collected during prior runs of a workflow are used to inform future optimisations.
Jumping ahead slightly to the evaluation, Gog et al. compared the results of the automatic back-end selection compared to an expert decision-tree. As we saw yesterday, matching a given workflow to the right back-end is a complex proposition. With profiling information available, Musketeer always makes good or optimal choices.
By contrast, using the decision tree yields many poor choices. This is due to its inflexible decision thresholds and its inability to consider the benefits of operator merging and shared scans.
Now, we don’t know the details of what went into that decision tree. But since the designers of it have a lot of information about the characteristics of the different back-ends, it’s reasonable to assume it’s making decisions in a similar way that an expert might given a description of the workflow. So this is a powerful testimony to the value of Musketeer’s back-end selection process vs. what you might be able to achieve on your own. In particular, without Musketeer, you have to pick a back-end up front before you can take any measurements since you need to code the workflow for a specific system.
In addition to mapping an entire workflow to different backends, Musketeer can also map parts of a workflow to different systems. We find that this ability to explore many different combinations of systems can yield useful (and sometimes surprising) results.
How well does it work?
The authors implemented three batch workflows (TPC-H, top-shopper, and Netflix movie recommendation), three iterative workflows (PageRank, single-source shortest path, and k-means clustering), and one hybrid one (PageRank with a batch pre-processing stage) to assess how well Musketeer works.
The automated back-end selection worked well (see above), and Musketeer was also able to find back-end system combinations that perform well. By retargeting existing legacy workflows, Musketeer obtained up to 2x speed-ups. Of particular interest is how well the back-end code performs compared to hand-optimised versions of the same workflow for the same back-end system.
For Musketeer to be attractive to some users, its generated code must add minimal overhead over an optimized hand-written implementation. In the following, we show that the overhead over an optimized baseline does not exceed 30% and is usually around 5–20%.
Remember that this is as compared to the best an expert programmer with good understanding of the back-end system can achieve. When non-experts are asked to perform the same tasks, Musketeer beats them handsomely:
To anecdotally compare the performance of Musketeer’s generated code to a baseline written by an average programmer, we asked eight CS undergraduate students to implement and optimize the simple JOIN workflow from §2.1 for a given input data set using Hadoop. The best student implementation took 608s, compared to the Musketeer-generated job at 223s. While not a rigorous evaluation, we take this as an indication that using Musketeer offers benefit for non-expert programmers.
And Musketeer will only get better as more and more optimisations are added. This puts me in mind of Stonebraker and Hellersteins ‘lesson 10’ from What Goes Around Comes Around (#themorningpaper no. 32):
“Query optimizers can beat all but the best record-at-a-time DBMS application programmers.” – Stonebraker & Hellerstein 2005.